vLLM 실행구조 파악하기 (v0.8.4)
Online and Offline inference
vLLM은 온라인과 오프라인, 두 가지 모드로 작동합니다. 오프라인 추론에서는 PyTorch 모듈과 유사하게 작동하여 입력 데이터로 실행할 수 있습니다. 반면 온라인 추론은 서버와 유사하게 작동합니다. 일단 시작되면 클라이언트의 요청을 기다리며 여러 요청을 동시에 처리할 수 있습니다.
두 모드 모두 겉보기에는 다르지만, 동일한 inference engine을 공유합니다.
서버, 엔진 초기화, 새로운 요청 처리, 엔진의 메인 루프, 그리고 스케줄러의 다섯 가지 코드 섹션을 살펴보겠습니다.
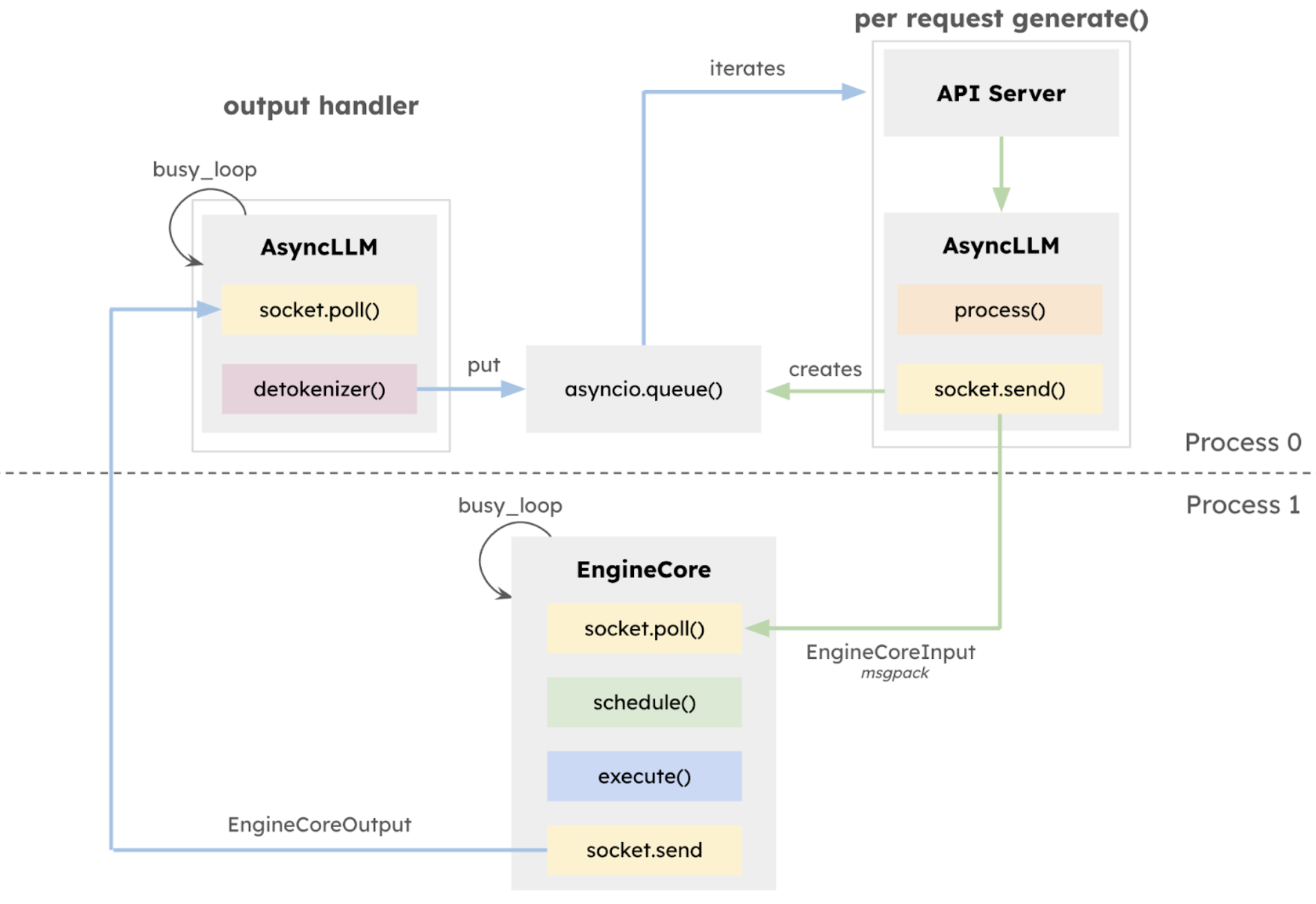
1. vLLM Server
vLLM은 FastAPI를 사용하여 서버를 호스팅합니다. 서버 내에서 AsyncLLMEngine이 인스턴스화됩니다. 이름과 달리 AsyncLLMEngine은 _AsyncLLMEngine이라는 실제 엔진의 래퍼 역할을 합니다.
서버가 출력을 생성하라는 요청을 받으면 다음 기능이 트리거됩니다.
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/entrypoints/openai/api_server.py
@router.post("/v1/completions", dependencies=[Depends(validate_json_request)])
@with_cancellation
@load_aware_call
async def create_completion(request: CompletionRequest, raw_request: Request):
handler = completion(raw_request) # OpenAIServingCompletion -> create_completion
if handler is None:
return base(raw_request).create_error_response(
message="The model does not support Completions API")
generator = await handler.create_completion(request, raw_request)
if isinstance(generator, ErrorResponse):
return JSONResponse(content=generator.model_dump(),
status_code=generator.code)
elif isinstance(generator, CompletionResponse):
return JSONResponse(content=generator.model_dump())
return StreamingResponse(content=generator, media_type="text/event-stream")# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/entrypoints/openai/serving_completion.py
class OpenAIServingCompletion(OpenAIServing):
async def create_completion(self,request: CompletionRequest,raw_request: Optional[Request] = None,):
request_id = f"cmpl-{self._base_request_id(raw_request)}"
# Schedule the request and get the result generator.
generators: list[AsyncGenerator[RequestOutput, None]] = []
for i, engine_prompt in enumerate(engine_prompts):
request_id_item = f"{request_id}-{i}"
...
# 서버는 엔진 래퍼의 generate 메서드를 호출
generator = self.engine_client.generate(engine_prompt,sampling_params,request_id_item,lora_request=lora_request, prompt_adapter_request=prompt_adapter_request,trace_headers=trace_headers, priority=request.priority,)
generators.append(generator)
...
# Streaming response
if stream:
return self.completion_stream_generator(request,result_generator, request_id,created_time, model_name, num_prompts=num_prompts,tokenizer=tokenizer, request_metadata=request_metadata)
# Non-streaming response
final_res_batch: list[Optional[RequestOutput]] = [None] * num_prompts
...엔진은 추론의 각 단계에서 하나의 토큰을 생성합니다. 스트리밍 요청의 경우, 서버는 생성된 토큰이 생성되는 즉시 반환하며, 전체 완료를 기다리지 않습니다. 반대로, 스트리밍이 아닌 요청의 경우, 서버는 전체 텍스트 완성이 생성될 때까지 기다린 후 클라이언트에 응답합니다.
2. 새로운 요청 처리
위에 설명된 대로, 서버는 엔진 래퍼의 generate 메서드를 호출하고 출력 토큰에 대한 generator를 가져옵니다.
generator = self.engine_client.generate(engine_prompt,sampling_params, request_id_item,...)generator 메서드는 add_request 메서드를 호출하여 얻은 반복자에서 간단히 결과를 생성합니다 .
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/engine/async_llm.py
async def generate(
self,
prompt: PromptType,
sampling_params: SamplingParams,
request_id: str,
lora_request: Optional[LoRARequest] = None,
trace_headers: Optional[Mapping[str, str]] = None,
prompt_adapter_request: Optional[PromptAdapterRequest] = None,
priority: int = 0,
) -> AsyncGenerator[RequestOutput, None]:
"""
Main function called by the API server to kick off a request => 결국 이 4개 항목 모두 add_request 에서 수행.
* 1) Making an AsyncStream corresponding to the Request.
* 2) Processing the Input.
* 3) Adding the Request to the Detokenizer.
* 4) Adding the Request to the EngineCore (separate process).
A separate output_handler loop runs in a background AsyncIO task,
pulling outputs from EngineCore and putting them into the
per-request AsyncStream.
The caller of generate() iterates the returned AsyncGenerator,
returning the RequestOutput back to the caller.
"""
try:
...
q = await self.add_request(
request_id,
prompt,
sampling_params,
lora_request=lora_request,
trace_headers=trace_headers,
prompt_adapter_request=prompt_adapter_request,
priority=priority,
)
finished = False
while not finished:
out = q.get_nowait() or await q.get()
finished = out.finished
yield out add_request 메서드를 호출하여 얻은 반복자에서 간단히 결과를 생성합니다 .
이제 add_request 메서드를 살펴보겠습니다.
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/engine/async_llm.py#L177
async def add_request(
self,
request_id: str,
prompt: PromptType,
params: Union[SamplingParams, PoolingParams],
arrival_time: Optional[float] = None,
lora_request: Optional[LoRARequest] = None,
trace_headers: Optional[Mapping[str, str]] = None,
prompt_adapter_request: Optional[PromptAdapterRequest] = None,
priority: int = 0,
) -> RequestOutputCollector:
"""Add new request to the AsyncLLM."""
assert isinstance(params, SamplingParams), \
"Pooling is not supported in V1"
# 1. Request에 해당하는 AsyncStream(비동기 스트림)을 생성합니다.
queue = RequestOutputCollector(output_kind=params.output_kind)
# 2. Input(입력)을 처리합니다
request = self.processor.process_inputs(request_id, prompt, params,
arrival_time, lora_request,
trace_headers,
prompt_adapter_request,
priority)
if params.n == 1:
await self._add_request(request, None, 0, queue)
return queue
async def _add_request(self, request: EngineCoreRequest,
parent_req: Optional[ParentRequest], index: int,
queue: RequestOutputCollector):
# 3. Request를 Detokenizer에 추가합니다.
self.output_processor.add_request(request, parent_req, index, queue)
# 4. Request를 EngineCore(별도 프로세스)에 추가합니다.
await self.engine_core.add_request_async(request)
이 함수의 목적은, 외부로부터 들어온 요청을 내부 처리 시스템의 큐에 등록하는 것입니다.
이 요청 등록 과정은 아래의 네 단계로 나뉩니다:
- (1) 요청에 대응되는 비동기 출력 스트림 생성
- (2) 요청 입력값을 전처리
- (3) 출력 후처리기(Detokenizer)에 요청 등록
- (4) 엔진 코어(EngineCore)에 요청 등록
이 결론이 맞는 이유를 설명드리겠습니다.
add_request()는SamplingParams인지 확인한 후, 요청을 처리할 준비를 합니다.- 먼저
RequestOutputCollector객체를 생성하여 출력 스트림을 준비합니다. - 그 다음
self.processor.process_inputs()를 호출하여 내부 요청 객체를 생성합니다. - 요청 수(
params.n)가 1인 경우에는_add_request()를 통해 Detokenizer + EngineCore에 등록합니다.
즉, 요청을 받아서 큐 두 개에 등록하는 작업만 담당하며, 출력 처리는 별도로 이뤄집니다.
3. 엔진 초기화
엔진 초기화는 workers, cache engine, scheduler의 초기화로 구성됩니다.
2.1. worker 초기화
v0 버전에서는 0번 GPU를 처리하는 worker를 메인 프로세스에서 실행하고, 나머지 worker들은 별도의 프로세스에서 실행하는 구조였습니다. 그러나 V1에서는 이러한 구조가 개선되어 모든 worker가 독립된 프로세스로 실행되며, 각 worker는 자신의 요청 상태를 캐시하고, 각 단계에서 증분 업데이트만 전송하여 통신 오버헤드를 줄입니다 .
이러한 변경 사항은 vLLM V1의 주요 개선 사항 중 하나로, 전체 시스템의 효율성과 유지 보수성을 향상시킵니다.
즉,
gpu_worker.py의Worker클래스는 모든 GPU에 대해 동일하게 초기화되며,is_driver_worker플래그는 존재하지만, 실질적으로 특별한 역할을 하지 않도록 설계되어 있습니다.
Worker클래스의 생성자 (__init__)에서is_driver_worker플래그는 존재는 합니다.
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/worker/gpu_worker.py
def __init__(...,
is_driver_worker: bool = False):
...
super().__init__(..., is_driver_worker=is_driver_worker)즉, 여전히 driver 역할 구분이 옵션 형태로 존재합니다. 하지만 중요한 점은 아래에서 알 수 있습니다:
execute_model()함수에서만is_driver_worker가 쓰이고 있으며, 반환 조건만 다릅니다.
@torch.inference_mode()
def execute_model(
self,
scheduler_output: "SchedulerOutput",
) -> Optional[ModelRunnerOutput]:
output = self.model_runner.execute_model(scheduler_output)
return output if self.is_driver_worker else None즉, 모든 worker가 동일한 방식으로 모델 실행을 수행하며, driver 역할을 하는 worker만 결과를 반환할 뿐입니다.
이 구조는 어떻게 독립적인 프로세스를 보장하는지는 init_worker_distributed_environment() 함수가 그 핵심입니다.
def init_worker_distributed_environment(
parallel_config: ParallelConfig,
rank: int,
distributed_init_method: Optional[str] = None,
local_rank: int = -1,
) -> None:
...
init_distributed_environment(...)각 worker는 이 함수 호출을 통해 분산 환경에서 독립적으로 초기화됩니다. 이 구조는 torch.distributed를 기반으로 프로세스를 분리하고, rank로 각 역할을 자동으로 구분하게 되어 있습니다.
2.2. cache engine 초기화
두 번째 단계는 캐시 엔진을 설정하는 것입니다.
각 워커는 자체 캐시 엔진을 가지고 있습니다.
각 캐시 엔진은 GPU에서 KV 캐시 저장소에 할당된 메모리를 관리합니다.
배치 크기를 최대화하기 위해 캐시 엔진은 가능한 한 많은 GPU 메모리를 사용하려고 합니다.
사용 가능한 메모리는 전체 GPU 메모리에서 모델 가중치 크기, intermediate activation size, 그리고 버퍼(일반적으로 전체 메모리의 10%)를 뺀 값입니다.
사용 가능한 메모리 = 전체 GPU 메모리 - 모델 가중치 크기 - intermediate activation size - 버퍼(일반적으로 전체 메모리의 10%)intermediate activation size
모델 크기는 이미 알려져 있지만, 중간 활성화 크기, 즉 추론 중 intermediate activation size에 사용되는 최대 메모리는 알려져 있지 않습니다. vLLM은 더미 데이터를 실행한 후 메모리 사용량을 프로파일링하여 이 값을 결정합니다. 더미 데이터의 크기는 구성의 매개변수에 의해 결정되며, 기본적으로 모델이 지원하는 최대 컨텍스트 길이로 설정됩니다.
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/worker/gpu_worker.py
class Worker(WorkerBase):
@torch.inference_mode()
def determine_available_memory(self) -> int:
"""
예를 들어, 캐시 블록 크기가 512KB이고 GPU 메모리 사용률을 0.9로 설정했을 때, 각 워커가 1000개, 950개, 900개의 GPU 블록을 사용할 수 있다고 응답한다면, 이 중 가장 적은 900개가 선택됩니다. CPU도 마찬가지입니다. 이후 이 설정을 바탕으로 캐시를 초기화하고 모델을 준비합니다.
"""
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
_, total_gpu_memory = torch.cuda.mem_get_info()
self.model_runner.profile_run()
free_gpu_memory, _ = torch.cuda.mem_get_info()
peak_memory = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
available_kv_cache_memory = (total_gpu_memory * self.cache_config.gpu_memory_utilization -peak_memory)
return int(available_kv_cache_memory)
vLLM은 torch.cuda.mem_get_info() 를 호출하여 더미 데이터 실행 후 최대 메모리 사용량을 가져옵니다. 이 사용량에는 가중치 크기와 중간 활성화 함수의 크기가 모두 포함되어야 합니다. 남은 GPU 메모리에서 메모리 버퍼를 빼면 캐시 엔진에서 사용할 수 있는 메모리가 생성됩니다.
vLLM은 운영 체제와 마찬가지로 GPU 메모리를 블록 단위로 관리합니다. 더 많은 KV 캐시를 저장하기 위해 추가 메모리가 필요하면 새 블록이 할당됩니다. 블록은 기본적으로 16개의 토큰을 포함합니다. 토큰당 KV 캐시 메모리 사용량은 다음 방정식을 사용하여 계산됩니다.
head_size * num_kv_heads * num_layers * dtype_size * 2사용 가능한 모든 메모리와 토큰 크기에 대한 지식을 바탕으로 vLLM은 저장할 수 있는 KV 캐시 토큰의 수를 결정할 수 있습니다.
캐시 엔진은 torch.empty를 호출하여 거대한 텐서를 생성하고 KV 캐시를 위해 막대한 메모리 덩어리를 예약합니다.
2.3. scheduler 초기화
마지막 단계는 스케줄러를 초기화하는 것입니다.
스케줄러는 logical KV cache IDs 와 그들의 physical storage locations 간의 매핑을 관리하는 kv cache manager를 생성합니다또한, 스케줄러는 running 큐, waiting 큐라는 2 개의 큐를 생성합니다. 스케줄러에 대한 자세한 내용은 나중에 설명합니다.
4. The Main Loop of the Engine
엔진은 항상 loop 상태에 있습니다. 대기열에 요청이 있는지 정기적으로 확인합니다. 요청이 있으면 모델을 한 단계 실행하고 루프가 계속 진행됩니다. 요청이 없으면 새 요청이 도착할 때까지 기다립니다. 아래 코드를 확인해 보세요.
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/engine/core.py
class EngineCore:
def __init__(
self,
input_path: str,
output_path: str,
vllm_config: VllmConfig,
executor_class: type[Executor],
log_stats: bool,
engine_index: int = 0,
):
self.step_fn = (self.step if self.batch_queue is None else
self.step_with_batch_queue)
"""Inner loop of vLLM's Engine."""
def run_busy_loop(self):
"""Core busy loop of the EngineCore."""
# Loop until process is sent a SIGINT or SIGTERM
while True:
# 1) Poll the input queue until there is work to do.
self._process_input_queue()
# 2) Step the engine core and return the outputs.
self._process_engine_step()
def _process_engine_step(self):
"""Called only when there are unfinished local requests."""
# Step the engine core.
outputs = self.step_fn()
# Put EngineCoreOutputs into the output queue.
if outputs is not None:
self.output_queue.put_nowait(outputs)그렇다면 step 이란 정확히 무엇일까요 ? 스텝은 vLLM 스케줄링에서 가장 작은 시간 단위입니다. 새로운 토큰을 생성하거나 새로운 프롬프트를 처리하는 데 사용됩니다.
Input queue에서 새 요청을 가져옵니다. 그런 다음 엔진을 호출하여 새 요청을 추가합니다. 엔진은 프롬프트를 인코딩하고, 요청에 대한 시퀀스 그룹을 생성하고, 스케줄러에 새 요청이 있음을 알립니다.
vLLM의 Sequence Group 은 요청과 관련된 모든 시퀀스를 포함합니다. Greedy 샘플링을 사용하면 시퀀스 그룹은 항상 하나의 시퀀스만 포함합니다. 그러나 BeamSearch을 사용하면 시퀀스 그룹에 여러 시퀀스가 포함될 수 있습니다.
그런 다음 엔진을 호출하여 한 단계 앞으로 진행합니다. 엔진의 step 메서드는 아래와 같습니다. 먼저 스케줄러가 이 반복에서 실행할 요청(시퀀스 그룹)을 결정하도록 합니다.
그런 다음 스케줄러의 결정을 워커에게 전달하여 GPU에서 모델을 실행하도록 합니다. 마지막으로 모든 출력을 수집하고 후처리 작업을 수행합니다.
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/engine/core.py
class EngineCore:
def step(self) -> EngineCoreOutputs:
"""Schedule, execute, and make output."""
# Check for any requests remaining in the scheduler - unfinished,
# or finished and not yet removed from the batch.
if not self.scheduler.has_requests():
# 스케줄러의 출력이 비어 있지 않은 경우 (즉, 실행할 작업이 있다면)
return EngineCoreOutputs(
outputs=[],
scheduler_stats=self.scheduler.make_stats(),
)
# 스케줄러가 이 반복에서 실행할 요청(시퀀스 그룹)을 결정하도록 합니다.
scheduler_output = self.scheduler.schedule()
# 스케줄러의 결정을 워커에게 전달하여 GPU에서 모델을 실행하도록 합니다.
output = self.model_executor.execute_model(scheduler_output)
# 마지막으로 출력을 수집하고 후처리 작업을 수행합니다.
engine_core_outputs = self.scheduler.update_from_output(
scheduler_output, output) # type: ignore
return engine_core_outputs다음 섹션에서는 scheduler.schedule() 이 무엇을 하는지 살펴보겠습니다 .
5. Scheduling
1. 결론부터 말하면, vLLM V1은 prefill과 decode를 구분하지 않고, 모든 요청을 동일한 방식으로 처리합니다.
이유는 다음과 같습니다.
- 기존에는 prefill(프롬프트 기반 KV 캐시 생성)과 decode(KV 캐시를 사용한 토큰 생성)를 명확히 구분하여 처리하였습니다.
- V1에서는 이러한 구분을 제거하고, 사용자 제공 프롬프트 토큰과 모델이 생성한 출력 토큰을 동일하게 취급합니다.
구체적 예시:
- 스케줄링 결정은
{request_id: num_tokens}형태의 딕셔너리로 표현되며, 각 요청에 대해 처리할 토큰 수를 지정합니다. - 이러한 방식은 chunked prefill, prefix caching, speculative decoding 등의 기능을 지원하는 데 충분히 일반적입니다.
2. 스케줄러의 판단 기준은 해당 순서 입니다:
실행 중인 요청 먼저 스케줄링 (running requests)
선점된 요청이 없을 경우, 대기 중인 요청 스케줄링 (waiting requests)
vLLM 은 일반적으로 FCFS(first come first serve) rule 을따라 해당 순서대로 우선순위를 매깁니다. (다만, 특별한 경우(인코더 제약, LoRA 제약 등)에는 큰 요청을 건너뛰고 다음 요청들을 고려할 수도 있음)
RequestStatus 로 해당 상태들을 분기합니다.
3. vLLM은 일반적으로 FCFS(First Come First Serve) 정책을 따릅니다.
이유는 다음과 같습니다.
요청 큐에서 앞에 있는 요청부터 처리하며, 토큰 크기로 인해 중간 요청이 너무 크면 그 이후 요청들을 보지 않고 중단합니다.
구체적 예시:
- 요청들: 2k, 3k, 30k, 2k, 3k
- 한도: 25k
스케줄러는 매 단계("step")마다 다음을 수행합니다:
- 우선 실행 중인 요청의 decode 단계 스케줄링: 이미 prefill이 완료되고 토큰을 생성 중인 요청들
- 그 다음 대기 중인 요청의 prefill 스케줄링
- 요청들: 2k, 3k, 30k, 2k, 3k
- 첫 번째 단계에서:
- 2k와 3k를 prefill (5k 토큰)
- 30k는 너무 커서 이번 스텝에 처리 못함
- 처리 못한 요청 뒤에 있는 요청들은 고려하지 않음
- 다음 스텝에서:
- 이전에 prefill된 2k와 3k는 이제 decode 단계로 각각 1토큰씩 생성
- 30k 요청을 prefill 시도 (여전히 너무 크면 부분적으로 처리)
- KV 캐시 공간이 충분하면 계속 진행, 부족하면 가장 낮은 우선순위 요청 일시 중단
3. KV 캐시 swapping이 제거되었으며, 대신 프리엠션(preemption)과 리컴퓨트(recompute) 전략을 사용합니다
핵심 결론: vLLM은 naive 방식 대신 recompute 방식을 사용하여 성능을 높입니다.
naive 방식 (기존 방법):
- KV cache tensor를 GPU ↔ CPU로 그대로 전송
- tensor 크기는 수백 MB 수준 → 통신 오버헤드 매우 큼
- 현대 LLM의 병목(bottleneck)은 종종 이런 통신 비용
recompute 방식 (vLLM의 최적화):
- KV cache tensor는 삭제(drop)
- 대신 지금까지 생성된 토큰만 기억
- victim request를 복귀시킬 때:
- prompt와 생성된 토큰을 합쳐서 새로운 prompt로 만듬
- 이를 새로운 요청처럼 처리하여 KV cache 재계산
- 예시:
- prompt:
"San Francisco is" - generated:
"a city in" - → 새로운 prompt:
"San Francisco is a city in"으로 다시prefill
- prompt:
왜 이 방식이 좋은가?
prefill계산은 매우 빠름- 통신보다 계산이 더 효율적
- 결과적으로 전체 성능 향상
⚠️ 단, 이 전략은 beam search와는 호환되지 않음
→ beam search를 사용할 경우, naive 방식으로 fallback됨 (chunky KV cache를 통째로 복원)
# https://github.com/vllm-project/vllm/blob/v0.8.4/vllm/v1/core/sched/scheduler.py
class Scheduler(SchedulerInterface):
def schedule(self) -> SchedulerOutput:
scheduled_new_reqs: list[Request] = []
scheduled_resumed_reqs: list[Request] = []
scheduled_running_reqs: list[Request] = []
preempted_reqs: list[Request] = []
...
while True:
new_blocks = self.kv_cache_manager.allocate_slots(
request,
num_new_tokens,
num_lookahead_tokens=self.num_lookahead_tokens)
if new_blocks is None:
# The request cannot be scheduled.
# Preempt the lowest-priority request.
preempted_req = self.running.pop()
self.kv_cache_manager.free(preempted_req)
preempted_req.status = RequestStatus.PREEMPTED
preempted_req.num_computed_tokens = 0
if self.log_stats:
preempted_req.record_event(
EngineCoreEventType.PREEMPTED, scheduled_timestamp)
self.waiting.appendleft(preempted_req)
preempted_reqs.append(preempted_req)
if preempted_req == request:
# No more request to preempt.
can_schedule = False
break
else:
# The request can be scheduled.
can_schedule = True
break