
intro
Spark Join전략과 hint라는 주제로 공부를 해보았습니다.
광대한 스파크 세계.. 아직도 너무 모르는게 많네요, 열심히 공부해야겠습니다.
--
apache spark 에서 가장 자주 사용되는 변환 중 하나는 join 작업이다. apache spark 에서의 join은 개발자가, 키를 기반으로 두 개 이상의 데이터 프레임을 결합할 수 있게 한다. join 동작 구문은 단순하지만, 그 뒤에 동작하는 내용이 손실되는 경우가 왕왕있다. 내부적으로 apache spark 는 join 알고리즘을 제안해, 그 중 하나(BroadcastHash Join, Sort Merge Join, Shuffle Hash Join,Cartesian Product (=shuffle_replicate_nl))를 선택하는데, 내부 알고리즘을 알아야, 몰라서 생기는 join 비용을 줄일 수 있다.
우리가 생각해야할점은, " 큰 테이블을 작은 테이블과 조인" 하거나 "큰 테이블을 다른 큰 테이블과 조인" 할 때이다. 어떻게, 조인할 것이냐, 라고 생각할때, 한 노드에 큰 규모의 데이터가 있고, 다른 노드에 작은 규모의 데이터가 있어서, 둘을 조인하다고 할 때, 당연히 작은 규모의 데이터를 큰 규모의 데이터가 있는 노드에 옮기는 것이 나을 것이라는 생각이 들것이다. 이런 작은 테이블을 전체 큰 데이터 있는 노드에 뿌리겠다는 전략, 이게 바로 Broadcast Hash Join 이다.
그렇다면, "큰 테이블과 큰테이블을 조인하는 방법"은? 노드가 여러개 있다고 할때, 우리는 조인키값으로 정렬해서, 주변에서 매핑되는 데이터 프레임끼리 머지하는 전략을 생각하거나(sort merge join), 해쉬처럼 맵리듀스전략을 이용해, 상대적으로 작은 테이블의 키값으로 큰 데이터를 매핑한후, 셔플을 통해 join key 가 같은 것 끼리 join을 수행하는 전략을 생각할 수 있다(shuffle hash join).
join 알고리즘을 선택할때, spark 는 관련된 데이터 프레임크기를 확인한다. 지정된 join 유형과 개발자가 명시한 hint 를 고려해, 최종적으로 사용할 알고리즘을 선택한다. 대부분의 경우, Sort Merge Join 과, Shuffle Hash join 은 spark sql join 을 구동하는 주 알고리즘이다. 그러나, 스파크가 데이터 프레임 중 하나의 크기가 임계값보다 작을 경우, 스파크는 broadcast join 을 우선시한다.
tip: join type check
q.explain : 조인문에 explain 을 넣으면 된다.
hint
- https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-hints.html
- 말그대로 hint 이다. 힌트는 Spark SQL이 실행 계획을 생성하기 위해 특정 접근 방식을 사용하는 방법을 제안하는 방법을 제공한다. Hint Framework 는 Spark SQL 2.2. 부터 도입되었다.
조인 힌트
- 조인 힌트를 통해 사용자는 Spark가 사용해야 하는 조인 전략을 제안할 수 있다.
- Spark 3.0 이전에는
BROADCASTJoin Hint만 지원되었다.MERGE,SHUFFLE_HASH그리고,SHUFFLE_REPLICATE_NLJoint 관련힌트는 3.0부터 추가되었다. - 조인의 양쪽에 서로 다른 조인 전략 힌트가 지정되면, Spark는
BROADCAST->SHUFFLE_HASH->SHUFFLE_REPLICATE_NL구으로 고려한다. 양쪽이BROADCAST,SHUFFLE_HASH를 가졌으면, Spark는 join type과 관계의 크기를 기반으로 빌드 쪽을 선택한다. 주어진 전략이 모든 조인 유형을 지원하지 않을 수 있으므로 Spark는 힌트에서 제안한 조인 전략을 사용하지 않을 수 있다. - 조인힌트 타입
- BROADCAST
autoBroadcastJoinThreshold제한 관계없이, 브로드캐스트 조인 이용가능
- MERGE
- shuffle sort merge join 제안
- =
MERGE=SHUFFLE_MERGE=MERGEJOIN.
- SHUFFLE_HASH
- shuffle hash join 제안
- SHUFFLE_REPLICATE_NL
- shuffle-and-replicate nested loop join(카다시안곱)을 제안한다.
- BROADCAST
- 예시 출처 : https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-hint-framework.html#specifying-query-hints
// Dataset API
val q = spark.range(1).hint(name = "myHint", 100, true)
val plan = q.queryExecution.logical
scala> println(plan.numberedTreeString)
00 'UnresolvedHint myHint, [100, true]
01 +- Range (0, 1, step=1, splits=Some(8))/*+ hint [ , ... ] */
# SQL
val q = sql("SELECT /*+ myHint (100, true) */ 1")
val plan = q.queryExecution.logical
scala> println(plan.numberedTreeString)
00 'UnresolvedHint myHint, [100, true]
01 +- 'Project [unresolvedalias(1, None)]
02 +- OneRowRelationjoin 전략 종류
Broadcast Hash Join
- = map-side join(associating worker nodes with mappers).
- aka. 작은 것을 모든 executor 에 복사한다. (셔플 안해서, 시간 성능 이득 )
- all to all communication 방법으로 shuffle 할 필요가 없다.
- 각 executor 에서는 보유하고 있는 보유하고 있는 큰 테이블의 일부와 broadast 된 테이블을 join 한다.
-
import org.apache.spark.sql.functions.broadcast val joinDF=bigDF.join(broadcast(smallDF), "foo") // or bigDF.join(smallDF.hint("broadcast"), Seq("foo"))- 구조도

- 스파크 ui 상 구조

- 위에 계획에서 보면, 하나의 데이터프레임이 다른데이터 프레임을포함하는 모든 노드에 브로드캐스트되는 것을 나타내고 있다. 그런 다음, 각 노드에서 spark 가 마지막 join 작업을 수행한다. 이것의 spark 의 노드별 커뮤니케이션의 전략이다.
- spark는 데이터 프레임의 크기중 하나가
spark.sql.autoBroadcast.Join에 설정된 임계값보다 작을때, 브로드캐스트해시 조인을 이용한다. 임계값은 기본값이 10mb 이지만, 다음 코드를 이용해 변경할 수 있다.
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 100 * 1024 * 1024)- 이 알고리즘은 조인의 다른 쪽에는 셔플이 필요하지 않다는 장점이 있다. 반대쪽이 매우 큰 경우, 셔플을 하지 않으면, 셔플을 해야하는 다른 알고리즘에 비해 속도가 현저히 향상한다.
- 대규모 데이터 세트를 브로드캐스트하면 시간초과오류가 발생할 수 있다 .
spark.sql.broadcastTimeout로 브로드캐스트 조작이 실패하는 최대 시간을 설정합니다. 기본 타임아웃값은 5분이지만, 다음과 같이 설정할 수 있다.
spark.conf.set("spark.sql.broadcastTimeout", time_in_sec)Shuffle Sort Merge Join
- aka. *all-to-all communication(모든 노드간의 all to all communication) *
- 스파크2.3 이후 default 조인 전략
- 어떤 데이터프레임도 브로드캐스트를 할 수 없는 경우, spark 는 sort merge join 을 선택한다. 이 알고리즘은 노드-노드 통신 전략을 이용해, spark 가 클러스터 전체에서 데이터를 교환한다.
수행방식
- 먼저 실제 join 작업을 수행하기 전에, join key 순으로 파티션들을 정렬한다. (이 작업만으로 비용이 크다.)
- 정렬된 데이터들을 병합하면서, join key 가 같은 row 들을 Join 한다.
- 구조도

- 스파크 ui 상 구조도

이 알고리즘은 2개의 스텝으로 구성된다. 첫번째 단계에서는 데이터셋을 교환 및 정렬하고, 두번째 단계에서는 요소를 반복하여 결합키에 따라, 동일한값을 가진 행을 결합함으로써 파티션에서 정렬된 데이터를 병합한다.
- 셔플과 정렬은 매우 비용이 많이 드는 작업이고, 원칙적으로 이러한 작업을 피하기 위해서는 올바른 버킷테이블에서 데이터프레임을 생성하는 것이 좋다. (= join 실행효율 향상)
- sort merge join 은 shuffle hash join 과 비교했을 때, 클러스터 내 데이터 이동이 더 적은 경향이 있다.
- spark2.3 부터 merge sort join 은 스파크의 기본 조인 알고리즘이다. 하지만 이 시간도,
spark.sql.join.preferSortMergeJoin을true로 하면, 시간을 줄일 수 있다. (양 테이블의 크기 비교 시간을 줄여주는 듯) - 데이터를 정렬하는데에 코스트가 좀 있다. 특수한 상황(broadCast 하기엔 작은테이블이 너무 크지만, 두 테이블 간의 데이터 차이가 3배 이상 날 때)에서, shuffle hash Join 보다 느릴 가능성이 있지만, 대다수의 경우, 클러스터 내 데이터 이동이 shuffle hash Join 보다 적어, 보다 효율적이다.
이상적인 성능을 발휘하려면
- join 될 파티션들이 최대한 같은 곳에 위치해야한다. 그렇지 않으면, 파티션들을 이동시키기 위해 대량의 shuffle이 발생한다.
- dataframe의 데이터가 클러스터에 균등하게 분베돼있어야한다. 그렇지 않으면, 특정 노드에 부하가 집중되고, 연산속도 느려진다.
- 병렬처리가 이뤄지려면, 일정한 수의 고유키가 존재해야한다.
Shuffled Hash Join
- aka. map-reduce 에 기반한 join 방식이다.
- 브로드캐스트 조인을 할 수 없을때 실행된다.
수행 방식
- shuffle phase: 두 데이터 세트가 셔플링된다.
- hash join phase: 더 작은 쪽 데이터가 해시 버킷화되고, 모든 파티션에서 더 큰쪽과 해시조인된다.
이용방법
- 이용하려면, spark 는 디폴트로 sort merge join 을 이용하므로
spark.sql.join.preferSortMergeJoin옵션을false로 변경해야한다. - 해시 테이블을 만드는 것은 비용이 많이 들고 테이블 중 하나가 다른 테이블보다 3배 이상 작을 때만 수행할 수 있다.
- 크기 측정 : 모든 속성 타입 크기의 합에 행 수를 곱한 값으로 추정한다.
- 각 파티션의 평균 크기가 autoBroadcastJoin 의 임계값보다 작을 경우에 수행여지를 고려한다.
- 데이터를 정렬할 필요가 없기 때문에, 특수한 상황(broadCast 하기엔 작은테이블이 너무 크지만, 두 테이블 간의 데이터 차이가 3배 이상 날때)에서, Sort Merge Join 보다 빠를 가능성이 있다. 클러스터 내 데이터 이동이 sort merge join 보다 더 많은 경향이 있다.

예시
// https://blog.madhukaraphatak.com/spark-3-introduction-part-9
spark.conf.set("spark.sql.autoBroadcastJoinThreshold", 1)
spark.conf.set("spark.sql.join.preferSortMergeJoin", false)
val shuffleHashJoin = salesDf.hint("shuffle_hash").join(customerDf,"customerId")Cartesian Product (=shuffle_replicate_nl)
- 조인 키 필요 없는 카다시안곱 그자체
- Cartesian Product 는 모든 행을 사용하여 두 데이터 프레임을 결합하는 조인 유형 중 하나이다.
- 이 조인은
shuffle_replicate_nl힌트를 사용하여 강제할 수 있다.
val cartesianProduct = salesDf.hint("shuffle_replicate_nl").join(customerDf)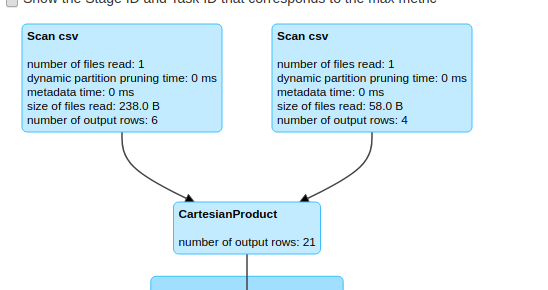
효율적인 join 을 방해하는 것들
- data skewness : join key 가 클러스터에 균일하게 분포해있지 않으면, 특정 파티션이 매우 커질 수 있다. 이는 spark 가 parallerl 하게 연산을 수행하는 것을 방해한다.
- 해결방법
- repartitioning
- key salting: salting 기법은 데이터 쏠림이 발생하여 문제가 되는 상황을 해결하기 위한 기법으로, 기본적으로는 새로운 join key를 추가하여 데이터를 더 잘개 쪼개주는 것 (참고 문헌 : https://towardsdatascience.com/skewed-data-in-spark-add-salt-to-compensate-16d44404088b)
-
df.withColumn("salt_random_column", (rand * n).cast(IntegerType)) // n is the size of partition you'd like to have (1. 새로운 난수 추가) .groupBy(groupByFields, "salt_random_column") //( 2. 이 새 필드와 기존 키를 복합 키로 결합하고 변환을 수행합니다.) .agg(aggFields) .groupBy(groupByFields)//3. 처리가 완료되면 최종 결과를 결합합니다. .agg(aggFields)
-
- all to all communication : broadcast join 이 아닐 경우, 두 df 의 데이터 모두에서 대규모 shuffle 이 발생한다.
- limited executor memory
결론
apache spark 는 join의 내부적으로 최상의 join 알고리즘을 선택하지만, 개발자는 hint를 이용하며, 이러한 결정에 영향을 미칠 수 있다. join 구문에 hint 를 지정하면, 개발자는 spark 가 거의 주로, 안하는 일을 요청할 수 있다.그래서, 기본 데이터 특성을 이해하지 않고, 힌트를 지정하면, oom 오류가 발생하거나, 대규모 파티션용 해시맵이 구축될 수 있으니, 기본 데이터에 대한 적합한 이해도와 함께, 이용한다면, join 작업을 최적화 할 수 있다.
참고 문헌
- https://blog.madhukaraphatak.com/spark-3-introduction-part-9
- https://towardsdatascience.com/strategies-of-spark-join-c0e7b4572bcf
- https://issues.apache.org/jira/browse/SPARK-27225
- https://spark.apache.org/docs/3.0.0-preview/sql-performance-tuning.html#join-strategy-hints-for-sql-queries
- spark sql hint https://spark.apache.org/docs/latest/sql-ref-syntax-qry-select-hints.html
- sql hint best example : https://jaceklaskowski.gitbooks.io/mastering-spark-sql/content/spark-sql-hint-framework.html#specifying-query-hints
- spark hint example : https://stackoverflow.com/questions/37487318/spark-sql-broadcast-hash-join
- join type: https://dhkdn9192.github.io/apache-spark/spark-join-strategy/
- join : https://blog.knoldus.com/joins-in-apache-spark/
- when we use shuffle hash join : https://www.hadoopinrealworld.com/how-does-shuffle-hash-join-work-in-spark/
- join : https://towardsdatascience.com/the-art-of-joining-in-spark-dcbd33d693c
- spark salting : https://towardsdatascience.com/skewed-data-in-spark-add-salt-to-compensate-16d44404088b
- spark salting :https://mesh.dev/20220130-dev-notes-008-salting-method-and-examples/
- shuffle join : https://www.waitingforcode.com/apache-spark-sql/shuffle-join-spark-sql/read
- sort merge join : https://www.waitingforcode.com/apache-spark-sql/sort-merge-join-spark-sql/read
'스파크' 카테고리의 다른 글
| 스파크 튜닝 관련 20230409 (0) | 2023.04.09 |
|---|---|
| Spark Dataset 개념과 이해 (0) | 2022.07.24 |
| Spark: Cluster Computing with Working Sets 정리(해석) (0) | 2022.05.22 |