
- Kubeflow Pipeline이란?
- Kubeflow pipeline Concept
- 컴파일러 호출
dsl-compile명령어 함수 분석- 파이프라인 YAML 파일 컴파일 과정 + 컴파일된 리소스 확인
Kubeflow Pipeline이란?
Kubeflow Pipelines is a platform for building and deploying portable, scalable machine learning (ML) workflows based on Docker containers.
Kubeflow Pipeline은 Docker 컨테이너를 기반으로 한 확장 가능한 휴대용 기계 학습(ML) 워크플로우를 구축하고 배포하기 위한 플랫폼입니다.
What is Kubeflow Pipelines?
The Kubeflow Pipelines platform은 이것들로 구성됩니다.
- experiments, jobs, and runs들을 관리하고 추적하기 위한 ui
- multi-step ML workflows를 스케줄링 하는 엔진
- pipeline 과 components 들을 정의하고 조작하기 위한 sdk
- sdk 를 이용해 시스템과 interact를 위한 notebook
What is a pipeline?
A pipeline is a description of an ML workflow, including all of the components in the workflow and how they combine in the form of a graph.
- 파이프라인은 ML 워크플로우에 대한 설명으로, 워크플로우의 모든 구성요소와 이러한 구성요소가 그래프 형태로 결합되는 방법을 포함합니다.
A pipeline component is a self-contained set of user code, packaged as a Docker image, that performs one step in the pipeline. For example, a component can be responsible for data preprocessing, data transformation, model training, and so on.
more detail .. https://www.kubeflow.org/docs/components/pipelines/v1/introduction/
Architectural overview
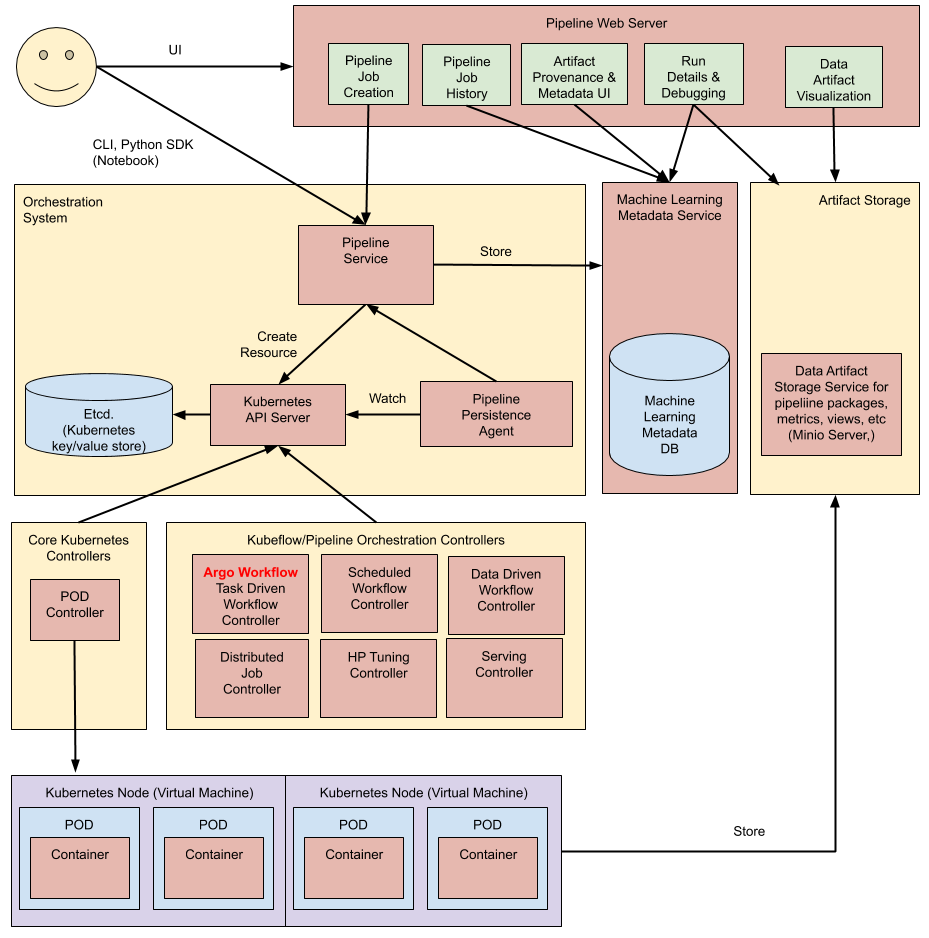
high level에서 파이프라인의 실행은 다음과 같이 진행됩니다:
Python SDK: Kubeflow Pipelines domain-specific language (DSL) 를 이용해 우리는 Pipeline 을 create components or specify할 수 있습니다.
DSL compiler: DSL compiler 는 너의 pipeline’s Python code를 static configuration (YAML)로 변환시켜 줍니다. 지금은 argo workflow 로 변환한다고 볼 수 있지만, v2 버전이 stable 이 되면, IRYaml 이 중간자로 될 수 있으니, yaml 로 알 고 있는 것이 좋습니다.
Pipeline Service: create a pipeline run from the static configuration 을 위해 Pipeline Service 를 이용합니다
Kubernetes resources: The Pipeline Service 는 the Kubernetes API server를 pipeline 을 run 하기 위한 CRD(Kubernetes resources (CRDs) ) 호출에 이용합니다.
- scheduled workflow , viewer..
Orchestration controllers: A set of orchestration controllers은 파이프라인을 완료하는 데 필요한 컨테이너를 실행합니다.. 컨테이너들은 virtual machine 의 Pod 내에서 execute됩니다. 예시로 task-driven workflows controller 인 argo workflow 가 있습니다.
Artifact storage: The Pods store two kinds of data:
Metadata:
- 구성: Experiments, jobs, pipeline runs, and single scalar metrics.
- 목적: Metric data is aggregated for the purpose of sorting and filtering.
- Kubeflow Pipelines 는 MySQL database에 메타데이터를 저장합니다.
Artifacts:
- 구성: Pipeline packages, views, and large-scale metrics (time series).
- 목적 : 디버깅, 런 퍼포먼스 조사
- Use large-scale metrics to debug a pipeline run or investigate an individual run’s performance.
- 저장 : Minio server or Cloud Storage.
The MySQL database and the Minio server are both backed by the Kubernetes PersistentVolume subsystem.
Persistence agent and ML metadata:
- Pipeline Persistence Agent는 파이프라인 서비스에서 생성된 Kubernetes 리소스를 감시하고 ML Metadata Service에서 이러한 리소스의 상태를 유지합니다.
- Pipeline Persistence Agent는 실행된 컨테이너 세트와 해당 입력 및 출력을 기록합니다. 입력/출력은 컨테이너 매개 변수 또는 데이터 아티팩트 URI로 구성됩니다.
Pipeline web server:
- Pipeline web server는 다양한 서비스에서 데이터를 수집하여 현재 실행 중인 파이프라인 목록, 파이프라인 실행 기록, 데이터 아티팩트 목록, 개별 파이프라인 실행에 대한 디버깅 정보, 개별 파이프라인 실행에 대한 실행 상태 등 관련 보기를 표시합니다.
Kubeflow pipeline Concept
- pipeline
- components
- graph
- experiment
- run and recurring run
- run trigger
- step
- output artifact
- ml metadata
컴파일러 호출
dsl-compile 명령어 함수 분석
- https://github.com/kubeflow/pipelines/blob/sdk/release-1.8/sdk/python/kfp/compiler/main.py
- 내부에서
kfp.compile을 호출한다.
def compile_pyfile(pyfile, function_name, output_path, type_check,
mode: Optional[dsl.PipelineExecutionMode]):
sys.path.insert(0, os.path.dirname(pyfile))
try:
filename = os.path.basename(pyfile)
with PipelineCollectorContext() as pipeline_funcs:
__import__(os.path.splitext(filename)[0])
_compile_pipeline_function(pipeline_funcs, function_name, output_path,
type_check, mode)
finally:
del sys.path[0]
def _compile_pipeline_function(pipeline_funcs, function_name, output_path,
type_check,
mode: Optional[dsl.PipelineExecutionMode]):
if len(pipeline_funcs) == 0:
raise ValueError(
'A function with @dsl.pipeline decorator is required in the py file.'
)
if len(pipeline_funcs) > 1 and not function_name:
func_names = [x.__name__ for x in pipeline_funcs]
raise ValueError(
'There are multiple pipelines: %s. Please specify --function.' %
func_names)
if function_name:
pipeline_func = next(
(x for x in pipeline_funcs if x.__name__ == function_name), None)
if not pipeline_func:
raise ValueError('The function "%s" does not exist. '
'Did you forget @dsl.pipeline decoration?' %
function_name)
else:
pipeline_func = pipeline_funcs[0]
kfp.compiler.Compiler(mode=mode).compile(pipeline_func, output_path,
type_check)kfp.client.compile
- https://github.com/kubeflow/pipelines/blob/sdk/release-1.8/sdk/python/kfp/compiler/compiler.py#L1129
- 스스로 클래스에서
_create_and_write_workflow를 호출한다.
def compile(self,
pipeline_func,
package_path,
type_check: bool = True,
pipeline_conf: Optional[dsl.PipelineConf] = None):
"""Compile the given pipeline function into workflow yaml.
Args:
pipeline_func: Pipeline functions with @dsl.pipeline decorator.
package_path: The output workflow tar.gz file path. for example,
"~/a.tar.gz"
type_check: Whether to enable the type check or not, default: True.
pipeline_conf: PipelineConf instance. Can specify op transforms, image
pull secrets and other pipeline-level configuration options. Overrides
any configuration that may be set by the pipeline.
"""
pipeline_root_dir = getattr(pipeline_func, 'pipeline_root', None)
if (pipeline_root_dir is not None or
self._mode == dsl.PipelineExecutionMode.V2_COMPATIBLE):
self._pipeline_root_param = dsl.PipelineParam(
name=dsl.ROOT_PARAMETER_NAME, value=pipeline_root_dir or '')
if self._mode == dsl.PipelineExecutionMode.V2_COMPATIBLE:
pipeline_name = getattr(pipeline_func, '_component_human_name', '')
if not pipeline_name:
raise ValueError(
'@dsl.pipeline decorator name field is required in v2 compatible mode'
)
# pipeline names have one of the following formats:
# * pipeline/<name>
# * namespace/<ns>/pipeline/<name>
# when compiling, we will only have pipeline/<name>, but it will be overriden
# when uploading the pipeline to KFP API server.
self._pipeline_name_param = dsl.PipelineParam(
name='pipeline-name', value=f'pipeline/{pipeline_name}')
import kfp
type_check_old_value = kfp.TYPE_CHECK
compiling_for_v2_old_value = kfp.COMPILING_FOR_V2
kfp.COMPILING_FOR_V2 = self._mode in [
dsl.PipelineExecutionMode.V2_COMPATIBLE,
dsl.PipelineExecutionMode.V2_ENGINE,
]
try:
kfp.TYPE_CHECK = type_check
self._create_and_write_workflow(
pipeline_func=pipeline_func,
pipeline_conf=pipeline_conf,
package_path=package_path)
finally:
kfp.TYPE_CHECK = type_check_old_value
kfp.COMPILING_FOR_V2 = compiling_for_v2_old_value
_create_and_write_workflow
- https://github.com/kubeflow/pipelines/blob/sdk/release-1.8/sdk/python/kfp/compiler/compiler.py#LL1218C1-L1232C1
_create_workflow를 호출한다.
def _create_and_write_workflow(self,
pipeline_func: Callable,
pipeline_name: Text = None,
pipeline_description: Text = None,
params_list: List[dsl.PipelineParam] = None,
pipeline_conf: dsl.PipelineConf = None,
package_path: Text = None) -> None:
"""Compile the given pipeline function and dump it to specified file
format."""
workflow = self._create_workflow(pipeline_func, pipeline_name,
pipeline_description, params_list,
pipeline_conf)
self._write_workflow(workflow, package_path)
_validate_workflow(workflow)
_create_workflow
- https://github.com/kubeflow/pipelines/blob/sdk/release-1.8/sdk/python/kfp/compiler/compiler.py#L957
- 여기가 그럼 핵심 본체라는 것인데 면밀하게 살펴보자.
def _create_workflow(
self,
pipeline_func: Callable,
pipeline_name: Optional[Text] = None,
pipeline_description: Optional[Text] = None,
params_list: Optional[List[dsl.PipelineParam]] = None,
pipeline_conf: Optional[dsl.PipelineConf] = None,
) -> Dict[Text, Any]:
"""Internal implementation of create_workflow."""- 파이프라인 메타데이터 생성
pipeline_meta = _extract_pipeline_metadata(pipeline_func)여기 부분에서 pipeline 의 메타 데이터를 가져온다.sanitize_k8s_name하게 변환한 name, description 을 가져오는 것이 보인다.
pipeline_meta = _extract_pipeline_metadata(pipeline_func)
pipeline_meta.name = pipeline_name or pipeline_meta.name
pipeline_meta.description = pipeline_description or pipeline_meta.description
pipeline_name = sanitize_k8s_name(pipeline_meta.name)- param list 가져오기
- Param 파라미터로 들어온 것들과 함께, _pipeline_root_param 을 가지고 파라미터 리스트를 만든다.
params_list = params_list or []
if self._pipeline_root_param:
params_list.append(self._pipeline_root_param)
if self._pipeline_name_param:
params_list.append(self._pipeline_name_param)
for param in params_list:
default_param_values[param.name] = param.value
param.value = None
args_list = []
kwargs_dict = dict()
signature = inspect.signature(pipeline_func)
for arg_name, arg in signature.parameters.items():
arg_type = None
for input in pipeline_meta.inputs or []:
if arg_name == input.name:
arg_type = input.type
break
param = dsl.PipelineParam(
sanitize_k8s_name(arg_name, True), param_type=arg_type)
if arg.kind == inspect.Parameter.KEYWORD_ONLY:
kwargs_dict[arg_name] = param
else:
args_list.append(param)
- 파이프라인 생성
- pipeline_name 을 가지고,
dsl.Pipeline을 생성한다. 해당 이름은dsl_pipeline이라한다.pipeline_func을 실행한다.
- pipeline_name 을 가지고,
with dsl.Pipeline(pipeline_name) as dsl_pipeline:
pipeline_func(*args_list, **kwargs_dict)- pipeline conf 지정
- pipeline_conf 를 오버라이딩 혹은
dsl_pipelin.conf로 pipeline conf 를 지정한다.
- pipeline_conf 를 오버라이딩 혹은
pipeline_conf = pipeline_conf or dsl_pipeline.conf # Configuration passed to the compiler is overriding. Unfortunately, it's not trivial to detect whether the dsl_pipeline.conf was ever modified.
- exit handler validate
- dsl pipeline 의 exit handler 를 validate 한다.
self._validate_exit_handler(dsl_pipeline)- artifact 주입한다.
self._sanitize_and_inject_artifact(dsl_pipeline, pipeline_conf)- param list 두개를 머지한다.
# Fill in the default values by merging two param lists.
args_list_with_defaults = OrderedDict()
if pipeline_meta.inputs:
args_list_with_defaults = OrderedDict([
(sanitize_k8s_name(input_spec.name, True), input_spec.default)
for input_spec in pipeline_meta.inputs
])
if params_list:
# Or, if args are provided by params_list, fill in pipeline_meta.
for k, v in default_param_values.items():
args_list_with_defaults[k] = v
pipeline_meta.inputs = pipeline_meta.inputs or []
for param in params_list:
pipeline_meta.inputs.append(
InputSpec(
name=param.name,
type=param.param_type,
default=default_param_values[param.name]))
- op_transformers를 pod_labels 과 함께 지정한다.
op_transformers = [add_pod_env]
pod_labels = {
_SDK_VERSION_LABEL: kfp.__version__,
_SDK_ENV_LABEL: _SDK_ENV_DEFAULT
}
op_transformers.append(add_pod_labels(pod_labels))
op_transformers.extend(pipeline_conf.op_transformers)
- _create_pipeline_workflow 를 호출한다.
workflow = self._create_pipeline_workflow(
args_list_with_defaults,
dsl_pipeline,
op_transformers,
pipeline_conf,
)_create_pipeline_workflow
- 실질적으로 argo workflow 를 직접 쓰는 함수이다.
_create_workflow에서 중요한 인자 지정 이후, 실질적으로 argo workflow 포맷대로 쓰는 함수이다. - https://github.com/kubeflow/pipelines/blob/sdk/release-1.8/sdk/python/kfp/compiler/compiler.py#LL765C9-L765C35
def _create_pipeline_workflow(self,
parameter_defaults,
pipeline,
op_transformers=None,
pipeline_conf=None):
"""Create workflow for the pipeline."""
# Input Parameters
input_params = []
for name, value in parameter_defaults.items():
param = {'name': name}
if value is not None:
param['value'] = value
input_params.append(param)
# Making the pipeline group name unique to prevent name clashes with templates
pipeline_group = pipeline.groups[0]
temp_pipeline_group_name = uuid.uuid4().hex
pipeline_group.name = temp_pipeline_group_name
# Templates
templates = self._create_dag_templates(pipeline, op_transformers)
# Exit Handler
exit_handler = None
if pipeline.groups[0].groups:
first_group = pipeline.groups[0].groups[0]
if first_group.type == 'exit_handler':
exit_handler = first_group.exit_op
# The whole pipeline workflow
# It must valid as a subdomain
pipeline_name = pipeline.name or 'pipeline'
# Workaround for pipeline name clashing with container template names
# TODO: Make sure template names cannot clash at all (container, DAG, workflow)
template_map = {
template['name'].lower(): template for template in templates
}
from ..components._naming import _make_name_unique_by_adding_index
pipeline_template_name = _make_name_unique_by_adding_index(
pipeline_name, template_map, '-')
# Restoring the name of the pipeline template
pipeline_template = template_map[temp_pipeline_group_name]
pipeline_template['name'] = pipeline_template_name
templates.sort(key=lambda x: x['name'])
workflow = {
'apiVersion': 'argoproj.io/v1alpha1',
'kind': 'Workflow',
'metadata': {
'generateName': pipeline_template_name + '-'
},
'spec': {
'entrypoint': pipeline_template_name,
'templates': templates,
'arguments': {
'parameters': input_params
},
'serviceAccountName': 'pipeline-runner',
}
}
# set parallelism limits at pipeline level
if pipeline_conf.parallelism:
workflow['spec']['parallelism'] = pipeline_conf.parallelism
# set ttl after workflow finishes
if pipeline_conf.ttl_seconds_after_finished >= 0:
workflow['spec']['ttlStrategy'] = {'secondsAfterCompletion': pipeline_conf.ttl_seconds_after_finished}
if pipeline_conf._pod_disruption_budget_min_available:
pod_disruption_budget = {
"minAvailable":
pipeline_conf._pod_disruption_budget_min_available
}
workflow['spec']['podDisruptionBudget'] = pod_disruption_budget
if len(pipeline_conf.image_pull_secrets) > 0:
image_pull_secrets = []
for image_pull_secret in pipeline_conf.image_pull_secrets:
image_pull_secrets.append(
convert_k8s_obj_to_json(image_pull_secret))
workflow['spec']['imagePullSecrets'] = image_pull_secrets
if pipeline_conf.timeout:
workflow['spec']['activeDeadlineSeconds'] = pipeline_conf.timeout
if exit_handler:
workflow['spec']['onExit'] = exit_handler.name
# This can be overwritten by the task specific
# nodeselection, specified in the template.
if pipeline_conf.default_pod_node_selector:
workflow['spec'][
'nodeSelector'] = pipeline_conf.default_pod_node_selector
if pipeline_conf.dns_config:
workflow['spec']['dnsConfig'] = convert_k8s_obj_to_json(
pipeline_conf.dns_config)
if pipeline_conf.image_pull_policy != None:
if pipeline_conf.image_pull_policy in [
"Always", "Never", "IfNotPresent"
]:
for template in workflow["spec"]["templates"]:
container = template.get('container', None)
if container and "imagePullPolicy" not in container:
container[
"imagePullPolicy"] = pipeline_conf.image_pull_policy
else:
raise ValueError(
'Invalid imagePullPolicy. Must be one of `Always`, `Never`, `IfNotPresent`.'
)
return workflow파이프라인 YAML 파일 컴파일 과정 + 컴파일된 리소스 확인
예제 파이프 라인
kubeflow 예시를 활용한 dsl pipeline 예제이다.
# xgboost_training_cm.py
from kfp import components
from kfp import dsl
import os
from kubernetes.client import models as k8s
import kfp.gcp as gcp
confusion_matrix_op = components.load_component_from_url('https://raw.githubusercontent.com/kubeflow/pipelines/1.7.0/components/local/confusion_matrix/component.yaml')
dataproc_create_cluster_op = components.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/pipelines/1.7.0-rc.3/components/gcp/dataproc/create_cluster/component.yaml')
dataproc_delete_cluster_op = components.load_component_from_url(
'https://raw.githubusercontent.com/kubeflow/pipelines/1.7.0-rc.3/components/gcp/dataproc/delete_cluster/component.yaml')
_PYSRC_PREFIX = 'gs://ml-pipeline/sample-pipeline/xgboost' # Common path to python src.
@dsl.pipeline(
name='XGBoost Trainer',
description='A trainer that does end-to-end distributed training for XGBoost models.'
)
def xgb_train_pipeline(
project='your-gcp-project',
cluster_name='xgb-%s' % dsl.RUN_ID_PLACEHOLDER,
region='us-central1',
):
with dsl.ExitHandler(exit_op=dataproc_delete_cluster_op(
project_id=project,
region=region,
name=cluster_name
)):
_create_cluster_op = dataproc_create_cluster_op(
project_id=project,
region=region,
name=cluster_name,
initialization_actions=[
os.path.join(_PYSRC_PREFIX,
'initialization_actions.sh'),
],
image_version='1.2'
)
dsl.get_pipeline_conf().set_image_pull_secrets([
k8s.V1LocalObjectReference(name='harbor-infra'),
k8s.V1LocalObjectReference(name='harbor-service'),
])
dsl.get_pipeline_conf().set_timeout(500000)
dsl.get_pipeline_conf().add_op_transformer(
gcp.use_gcp_secret('user-gcp-sa'))
컴파일
직접 yaml 로 컴파일 해보자.
타입을 직접 추론해줬다는 로깅이 되면서 xgboost_training_cm.yaml 이 생성된다.
➜ 20230507 git:(master) ✗ dsl-compile --py xgboost_training_cm.py --output xgboost_training_cm.yaml
/usr/local/lib/python3.10/site-packages/kfp/components/_components.py:196: FutureWarning: Container component must specify command to be compatible with KFP v2 compatible mode and emissary executor, which will be the default executor for KFP v2.https://www.kubeflow.org/docs/components/pipelines/installation/choose-executor/
warnings.warn(컴파일된 리소스 확인
- argo 의 workflow 타입대로 들어온것을 확인할 수 있다.
kind: Workflow
metadata:
generateName: xgboost-trainer-
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.20, pipelines.kubeflow.org/pipeline_compilation_time: '2023-05-07T15:14:54.815009',
pipelines.kubeflow.org/pipeline_spec: '{"description": "A trainer that does end-to-end
distributed training for XGBoost models.", "inputs": [{"default": "your-gcp-project",
"name": "project", "optional": true}, {"default": "xgb-{{workflow.uid}}", "name":
"cluster_name", "optional": true}, {"default": "us-central1", "name": "region",
"optional": true}], "name": "XGBoost Trainer"}'}
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.8.20}
spec:
entrypoint: xgboost-trainer
templates:
- name: dataproc-create-cluster
container:
args: [--ui_metadata_path, /tmp/outputs/MLPipeline_UI_metadata/data, kfp_component.google.dataproc,
create_cluster, --project_id, '{{inputs.parameters.project}}', --region, '{{inputs.parameters.region}}',
--name, '{{inputs.parameters.cluster_name}}', --name_prefix, '', --initialization_actions,
'["gs://ml-pipeline/sample-pipeline/xgboost/initialization_actions.sh"]',
--config_bucket, '', --image_version, '1.2', --cluster, '', --wait_interval,
'30', --cluster_name_output_path, /tmp/outputs/cluster_name/data]
command: []
env:
- {name: KFP_POD_NAME, value: '{{pod.name}}'}
- name: KFP_POD_NAME
valueFrom:
fieldRef: {fieldPath: metadata.name}
- name: KFP_POD_UID
valueFrom:
fieldRef: {fieldPath: metadata.uid}
- name: KFP_NAMESPACE
valueFrom:
fieldRef: {fieldPath: metadata.namespace}
- name: WORKFLOW_ID
valueFrom:
fieldRef: {fieldPath: 'metadata.labels[''workflows.argoproj.io/workflow'']'}
- name: KFP_RUN_ID
valueFrom:
fieldRef: {fieldPath: 'metadata.labels[''pipeline/runid'']'}
- name: ENABLE_CACHING
valueFrom:
fieldRef: {fieldPath: 'metadata.labels[''pipelines.kubeflow.org/enable_caching'']'}
- {name: GOOGLE_APPLICATION_CREDENTIALS, value: /secret/gcp-credentials/user-gcp-sa.json}
- {name: CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE, value: /secret/gcp-credentials/user-gcp-sa.json}
image: gcr.io/ml-pipeline/ml-pipeline-gcp:1.7.0-rc.3
volumeMounts:
- {mountPath: /secret/gcp-credentials, name: gcp-credentials-user-gcp-sa}
inputs:
parameters:
- {name: cluster_name}
- {name: project}
- {name: region}
outputs:
artifacts:
- {name: mlpipeline-ui-metadata, path: /tmp/outputs/MLPipeline_UI_metadata/data}
- {name: dataproc-create-cluster-cluster_name, path: /tmp/outputs/cluster_name/data}
metadata:
labels:
add-pod-env: "true"
pipelines.kubeflow.org/kfp_sdk_version: 1.8.20
pipelines.kubeflow.org/pipeline-sdk-type: kfp
pipelines.kubeflow.org/enable_caching: "true"
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Creates
a DataProc cluster under a project.\n", "implementation": {"container":
{"args": ["--ui_metadata_path", {"outputPath": "MLPipeline UI metadata"},
"kfp_component.google.dataproc", "create_cluster", "--project_id", {"inputValue":
"project_id"}, "--region", {"inputValue": "region"}, "--name", {"inputValue":
"name"}, "--name_prefix", {"inputValue": "name_prefix"}, "--initialization_actions",
{"inputValue": "initialization_actions"}, "--config_bucket", {"inputValue":
"config_bucket"}, "--image_version", {"inputValue": "image_version"}, "--cluster",
{"inputValue": "cluster"}, "--wait_interval", {"inputValue": "wait_interval"},
"--cluster_name_output_path", {"outputPath": "cluster_name"}], "env": {"KFP_POD_NAME":
"{{pod.name}}"}, "image": "gcr.io/ml-pipeline/ml-pipeline-gcp:1.7.0-rc.3"}},
"inputs": [{"description": "Required. The ID of the Google Cloud Platform
project that the cluster belongs to.", "name": "project_id", "type": "GCPProjectID"},
{"description": "Required. The Cloud Dataproc region in which to handle
the request.", "name": "region", "type": "GCPRegion"}, {"default": "", "description":
"Optional. The cluster name. Cluster names within a project must be unique.
Names of deleted clusters can be reused", "name": "name", "type": "String"},
{"default": "", "description": "Optional. The prefix of the cluster name.",
"name": "name_prefix", "type": "String"}, {"default": "", "description":
"Optional. List of GCS URIs of executables to execute on each node after
config is completed. By default, executables are run on master and all worker
nodes.", "name": "initialization_actions", "type": "List"}, {"default":
"", "description": "Optional. A Google Cloud Storage bucket used to stage
job dependencies, config files, and job driver console output.", "name":
"config_bucket", "type": "GCSPath"}, {"default": "", "description": "Optional.
The version of software inside the cluster.", "name": "image_version", "type":
"String"}, {"default": "", "description": "Optional. The full cluster config.
See [full details](https://cloud.google.com/dataproc/docs/reference/rest/v1/projects.regions.clusters#Cluster)",
"name": "cluster", "type": "Dict"}, {"default": "30", "description": "Optional.
The wait seconds between polling the operation. Defaults to 30.", "name":
"wait_interval", "type": "Integer"}], "metadata": {"labels": {"add-pod-env":
"true"}}, "name": "dataproc_create_cluster", "outputs": [{"description":
"The cluster name of the created cluster.", "name": "cluster_name", "type":
"String"}, {"name": "MLPipeline UI metadata", "type": "UI metadata"}]}',
pipelines.kubeflow.org/component_ref: '{"digest": "79c566b98983ff3064db6ddb9ee314192758c98b7329594554abd700059195d6",
"url": "https://raw.githubusercontent.com/kubeflow/pipelines/1.7.0-rc.3/components/gcp/dataproc/create_cluster/component.yaml"}',
pipelines.kubeflow.org/arguments.parameters: '{"cluster": "", "config_bucket":
"", "image_version": "1.2", "initialization_actions": "[\"gs://ml-pipeline/sample-pipeline/xgboost/initialization_actions.sh\"]",
"name": "{{inputs.parameters.cluster_name}}", "name_prefix": "", "project_id":
"{{inputs.parameters.project}}", "region": "{{inputs.parameters.region}}",
"wait_interval": "30"}'}
volumes:
- name: gcp-credentials-user-gcp-sa
secret: {secretName: user-gcp-sa}
- name: dataproc-delete-cluster
container:
args: [kfp_component.google.dataproc, delete_cluster, --project_id, '{{inputs.parameters.project}}',
--region, '{{inputs.parameters.region}}', --name, '{{inputs.parameters.cluster_name}}',
--wait_interval, '30']
command: []
env:
- {name: KFP_POD_NAME, value: '{{pod.name}}'}
- name: KFP_POD_NAME
valueFrom:
fieldRef: {fieldPath: metadata.name}
- name: KFP_POD_UID
valueFrom:
fieldRef: {fieldPath: metadata.uid}
- name: KFP_NAMESPACE
valueFrom:
fieldRef: {fieldPath: metadata.namespace}
- name: WORKFLOW_ID
valueFrom:
fieldRef: {fieldPath: 'metadata.labels[''workflows.argoproj.io/workflow'']'}
- name: KFP_RUN_ID
valueFrom:
fieldRef: {fieldPath: 'metadata.labels[''pipeline/runid'']'}
- name: ENABLE_CACHING
valueFrom:
fieldRef: {fieldPath: 'metadata.labels[''pipelines.kubeflow.org/enable_caching'']'}
- {name: GOOGLE_APPLICATION_CREDENTIALS, value: /secret/gcp-credentials/user-gcp-sa.json}
- {name: CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE, value: /secret/gcp-credentials/user-gcp-sa.json}
image: gcr.io/ml-pipeline/ml-pipeline-gcp:1.7.0-rc.3
volumeMounts:
- {mountPath: /secret/gcp-credentials, name: gcp-credentials-user-gcp-sa}
inputs:
parameters:
- {name: cluster_name}
- {name: project}
- {name: region}
metadata:
labels:
add-pod-env: "true"
pipelines.kubeflow.org/kfp_sdk_version: 1.8.20
pipelines.kubeflow.org/pipeline-sdk-type: kfp
pipelines.kubeflow.org/enable_caching: "true"
annotations: {pipelines.kubeflow.org/component_spec: '{"description": "Deletes
a DataProc cluster.\n", "implementation": {"container": {"args": ["kfp_component.google.dataproc",
"delete_cluster", "--project_id", {"inputValue": "project_id"}, "--region",
{"inputValue": "region"}, "--name", {"inputValue": "name"}, "--wait_interval",
{"inputValue": "wait_interval"}], "env": {"KFP_POD_NAME": "{{pod.name}}"},
"image": "gcr.io/ml-pipeline/ml-pipeline-gcp:1.7.0-rc.3"}}, "inputs": [{"description":
"Required. The ID of the Google Cloud Platform project that the cluster
belongs to.", "name": "project_id", "type": "GCPProjectID"}, {"description":
"Required. The Cloud Dataproc region in which to handle the request.", "name":
"region", "type": "GCPRegion"}, {"description": "Required. The cluster name
to delete.", "name": "name", "type": "String"}, {"default": "30", "description":
"Optional. The wait seconds between polling the operation. Defaults to 30.",
"name": "wait_interval", "type": "Integer"}], "metadata": {"labels": {"add-pod-env":
"true"}}, "name": "dataproc_delete_cluster"}', pipelines.kubeflow.org/component_ref: '{"digest":
"ed957caecff54488362e8a979b5b9041e50d912e34f7022e8474e6205125169b", "url":
"https://raw.githubusercontent.com/kubeflow/pipelines/1.7.0-rc.3/components/gcp/dataproc/delete_cluster/component.yaml"}',
pipelines.kubeflow.org/arguments.parameters: '{"name": "{{inputs.parameters.cluster_name}}",
"project_id": "{{inputs.parameters.project}}", "region": "{{inputs.parameters.region}}",
"wait_interval": "30"}'}
volumes:
- name: gcp-credentials-user-gcp-sa
secret: {secretName: user-gcp-sa}
- name: exit-handler-1
inputs:
parameters:
- {name: cluster_name}
- {name: project}
- {name: region}
dag:
tasks:
- name: dataproc-create-cluster
template: dataproc-create-cluster
arguments:
parameters:
- {name: cluster_name, value: '{{inputs.parameters.cluster_name}}'}
- {name: project, value: '{{inputs.parameters.project}}'}
- {name: region, value: '{{inputs.parameters.region}}'}
- name: xgboost-trainer
inputs:
parameters:
- {name: cluster_name}
- {name: project}
- {name: region}
dag:
tasks:
- name: exit-handler-1
template: exit-handler-1
arguments:
parameters:
- {name: cluster_name, value: '{{inputs.parameters.cluster_name}}'}
- {name: project, value: '{{inputs.parameters.project}}'}
- {name: region, value: '{{inputs.parameters.region}}'}
arguments:
parameters:
- {name: project, value: your-gcp-project}
- {name: cluster_name, value: 'xgb-{{workflow.uid}}'}
- {name: region, value: us-central1}
serviceAccountName: pipeline-runner
imagePullSecrets:
- {name: harbor-infra}
- {name: harbor-service}
activeDeadlineSeconds: 500000
onExit: dataproc-delete-cluster참고 문헌
https://www.kubeflow.org/docs/
- v2, v1 https://github.com/kubeflow/pipelines/issues/7238
- https://www.kubeflow.org/docs/components/pipelines/v2/
- : Kubeflow Pipelines v2는 시험판 단계에 있으며 아직 안정적이지 않습니다. v2 문서는 지속적으로 개발되고 있으며 v2 문서에 대한 링크도 아직 안정적이지 않습니다