
llm-d is a Kubernetes-native distributed inference serving stack
https://llm-d.ai, https://github.com/llm-d
why llm-d
왜 llm-d 로 가야하는가는 명확합니다.
멀티노드의 vllm 을 쿠버네티스 위에 올리는 가장 , 이상적인 최적화된 방법이 무엇일까요? 쿠버네티스 만든 사람이 멀티노드 llm 서빙을 만드는 것입니다. 앗 그럼 멀티노드 llm 서빙을 쿠버네티스 하는 사람들이 모르면 어쩌죠? 현존하는 멀티노드 llm 서빙툴(예. production stack, kserve, dynamo )을 차용해 확장 가능하게끔 구현하면됩니다.
즉, llm-d 는 쿠버네티스 개발자들이 현존하는 멀티노드 llm 서빙툴을 차용해 확장 가능하게끔 구현한 멀티노드 llm 서빙툴입니다.
현재, llm-d 에 대한 관심은 나온지 일주일 됐다는것이 믿기지 않을만큼, star수가 꾸준히 증가하고 있습니다.
아키텍처

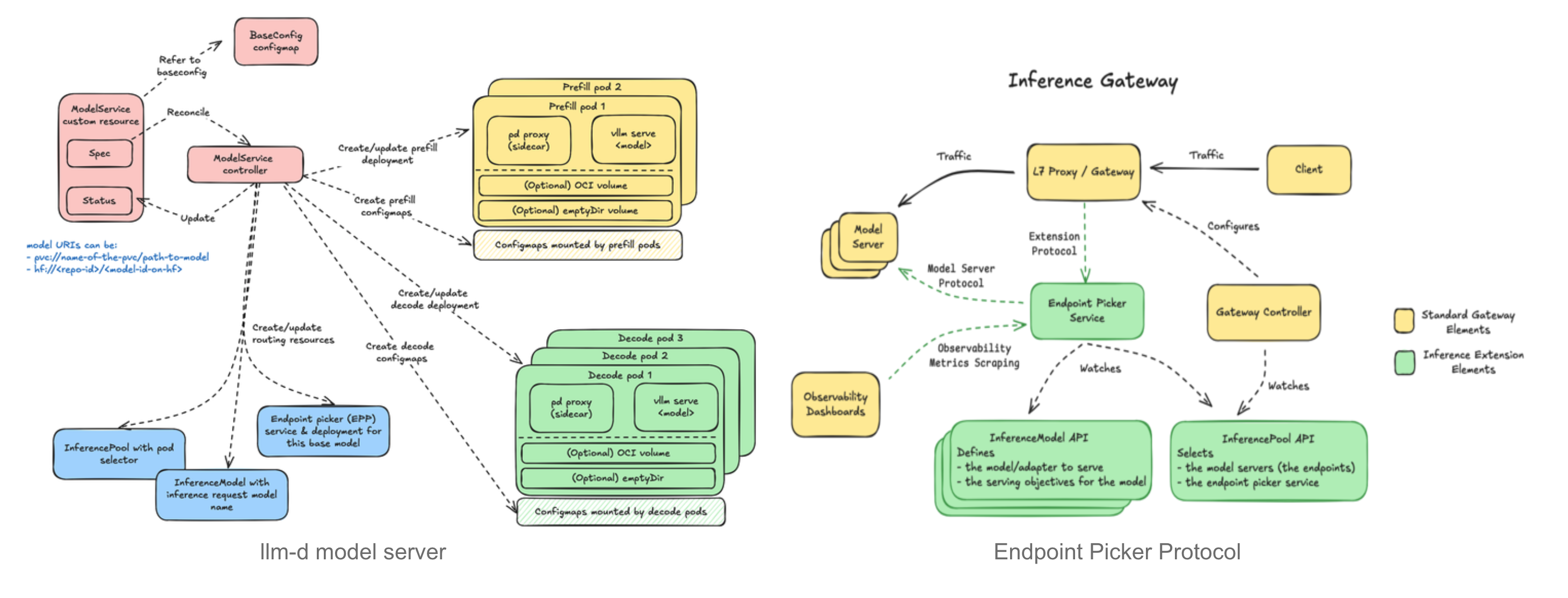
llm-d 에서 제시하는 아키텍처는 다음과 같습니다.
해당 아키텍처에서 가장 중요한 구성은 다음과 같습니다.
1. vLLM Optimized Inference Scheduler
2. Disaggregated serving
3. Disaggregated prefix caching with vLLM
4. Variant autoscaling over hardware, workload, and traffic
1. vLLM Optimized Inference Scheduler
LLM 최적화 추론 스케줄러 (LLM-Optimized Inference Scheduler)
llm-d는 IGW(Inference Gateway)의 "스마트" 로드 밸런싱을 위한 맞춤형 방식인 Endpoint Picker Protocol (EPP)를 기반으로 하여, vLLM에 최적화된 스케줄링 방식을 정의합니다.
vLLM이 노출하는 OpenTelemetry(GPU 부하, prefix cache hit 여부, latency 등)를 활용하여, 이 Inference Scheduler는 P/D(Prefill/Decode), KV-cache, SLA, 시스템 부하를 고려하는 1) 필터링(요청 처리 불가능한 노드는 제거) 및 2) 스코어링(각 후보노드에 점수 부여) 알고리즘을 실행해 인퍼런스 요청을 어디에 보낼지 결정합니다.
매력적인 점은, 자체 필터링, 스코어링 알고리즘 등을 구현할 수 있다는 점입니다.
Endpoint Picker Protocol (EPP)
EPP 프로토콜은, 쿠버네티스에서 구성한 model server protocol입니다.
EPP 핵심 구성은 이렇습니다.
- 모델을 추상화한 InferenceModel =모델의 논리적 라벨
- 서버 풀인 InferencePool = 인프라 자원 => 모델을 고치지 않고도 인프라 위치를 바꿀 수 있고, 같은 서버 풀에 여러 모델을 배치할 수도 있음.
- 엔드포인트를 결정하는 Endpoint Picker입니다. = 그걸 가지고 어디에 보낼지 로직을 담당
해당 EPP구조는 https://github.com/llm-d/llm-d-model-service model service 에서 구현을 유사하게 확인할 수 있습니다.
2. Disaggregated serving
llm-d는 vLLM의 분리형 서빙(disaggregated serving) 지원을 활용하여 prefill과 decode를 서로 다른 인스턴스에서 실행합니다. 또한, KV 캐시를 원격 GPU로 초고속 전송하기 위해 NVIDIA NIXL 통신 계층, 즉, 고성능 통신 라이브러리인 NIXL을 사용합니다.,
NIXL은 NVIDIA가 제공하는 고속 네트워크 통신 라이브러리로, 여러 인스턴스 간 통신 비용을 줄여 성능을 높일 수 있습니다. NCCL과의 다른점은 노드 추가 제거가 가능해, 기존에 노드 하나 장애시 다시 전체 노드가 다시 떠야하는 불편함을 제거했다고 생각해주시면될것같습니다.
또한. llm-d에서는 IB(InfiniBand), RDMA, ICI(Intel Compute Interconnect) 같은 저지연 인터커넥트를 활용한 latency-optimized 구현지원,데이터센터 네트워킹을 활용한 throughput 최적화 구현도 제공할 예정이라고 시사하고있습니다.
Disaggregated prefix caching
llm-d는 vLLM의 KVConnector API를 사용하여 이전 계산 결과(KV)를 위한 플러그형 캐시(pluggable cache)를 제공합니다.
이에는 호스트 메모리로의 오프로딩, 원격 스토리지, 그리고 LMCache와 같은 시스템으로의 연결이 포함됩니다.
두 가지 KV 캐싱 방식을 지원하는 것이 목표입니다.
- 독립형(North-South) 캐싱:
- KV 데이터를 로컬 메모리나 디스크로 오프로딩(offload)합니다.
- 이는 운영 비용이 0에 가까운 방식으로, 간단하게 오프로딩을 가능하게 합니다.
- 공유형(East-West) 캐싱:
- 인스턴스 간 KV를 전송하고, 공유 스토리지와 글로벌 인덱싱을 활용합니다.
- 이는 더 높은 성능을 달성할 수 있는 잠재력이 있지만, 운영 복잡도는 더 큽니다.
사용자 시나리오별 최적 캐싱 전략을 제시하고자 하는데요, 예시는 다음과 같습니다.
- 챗봇
- 낮은 latency 요구함.
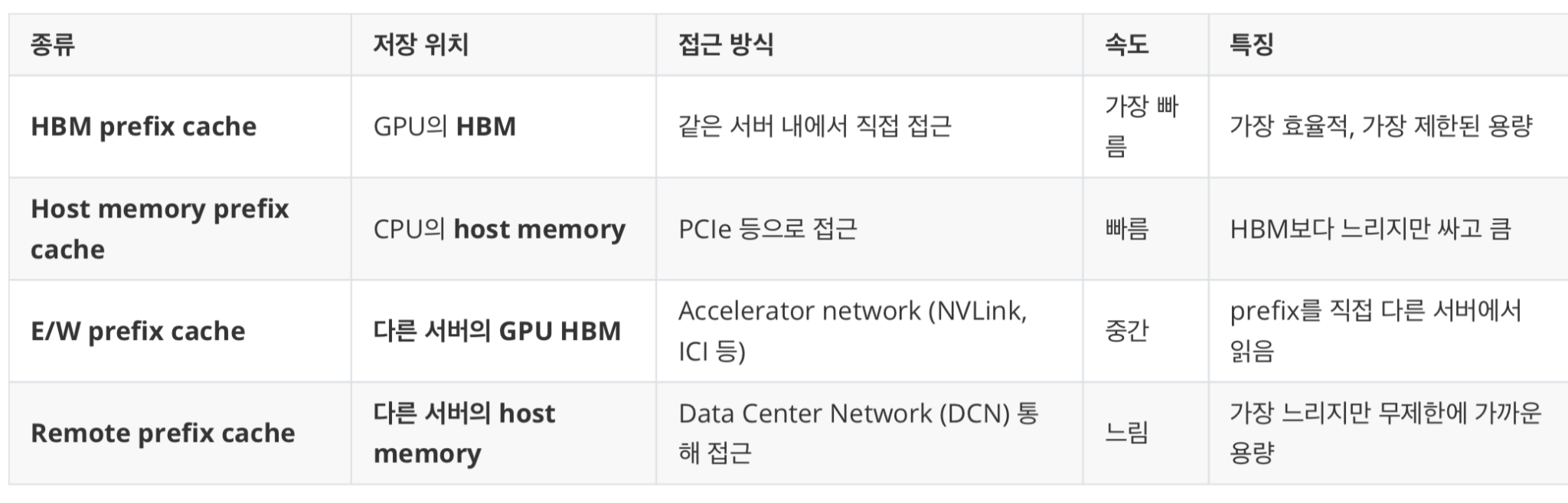
- HBM 비어있는데 스케줄해서 HBM 이용
- 도큐먼트 넣고 요약 요구함
- 상대적으로 늦어도되는데 long seq가 요구됨. 따라서 자주 쓰는 것만 HBM에 남기고,
- 덜 쓰는 것은 CPU memory에 spill하는 전략을 씁니다. (as. L1 Cache , L2 Cache, L3 Cache)
4. Autoscaling
- 1차적으로 목표를 AIBrix 차용을 목표로 진행하고 있습니다.
트래픽 및 하드웨어 인식형 오토스케일러를 구현 목표로 수행되고 있습니다. 이 오토스케일러는 다음과 같은 기능을 수행합니다:
(a) 각 모델 서버 인스턴스의 처리 용량(capacity) 을 측정하고,
(b) 요청 형태(request shape) 와 QoS(Quality of Service) 를 고려한 부하 함수(load function) 를 도출하며,
(c) 최근 트래픽 믹스(QPS, QoS, 요청 형태)를 분석합니다.
이러한 최근 트래픽 믹스를 기반으로, prefill 요청, decode 요청, 지연 허용 요청(latency-tolerant) 을 처리하기 위한 인스턴스의 최적 조합(optimal mix) 을 계산하여, HPA(Horizontal Pod Autoscaler) 를 통해 SLO 수준의 효율성을 달성할 수 있도록 합니다.
실제 PoC
해당 영상을 참고해 실제 pod 딴 내역을 살펴봄보면 다음과 같습니다.
https://www.youtube.com/watch?v=sBLdjDcYLvQ&t=355s
