
반응형
vLLM은 asyncLLMEngine이라는 클래스를 사용해 요청을 처리하며, 이 엔진은 *Continous Batching을 담당합니다. LLM 엔진은 VM 내부에서 작동하며, 루프를 실행하는데, 이 루프는 세 가지 단계로 구성됩니다: 첫 번째는 스케줄링(Scheduling), 두 번째는 실행(Executing), 세 번째는 출력 처리(Processing Outputs)입니다.
- 스케줄러(Scheduler)는 "무엇을 처리할지"를 결정합니다. 특정 요청이 완료되었는지, 새로운 요청이 들어왔는지를 확인하며,
이러한 요청을 처리하기 위해 KV 캐시에 필요한 메모리를 할당합니다.
본질적으로 스케줄러는 각 model executor 가 배칭 단계에서 수행해야 할 작업을 결정합니다. => 스파크드라이버랑 사실상 유사해.
- 모델 실행기(Model Executor)는
스케줄링된 작업을 가져와 GPU 워커에 전달하는 역할을 합니다. vLLM 내부에서는 텐서 병렬 처리(tensor parallelism)를 지원하며, 모델을 여러 GPU에 분산 처리합니다.
VM 내부에는 복잡한 레이어가 있어 입력 데이터를 준비하고 이를 각 워커에 브로드캐스트하는 작업을 처리합니다. 이 작업은 CPU에서 수행됩니다 => 스파크 익스큐터인데 cpu 로 돼있으니 , gpu 로 통신하는거지. 이거는 사실상, (스케줄러--> cpu ---> gpu ) 이렇게 되고,gpu 단위를 워커라 부르는 것. 여기 사이에 워커도 있고 러너도 있고 복잡한 레이어가 있는데 이 작업이 cpu 에서 수행된다.
- 마지막으로 모델이 실행된 이후에는 출력 처리(Processing Outputs)를 수행해야 합니다.
이 단계에서는 API 서버로 스트리밍하거나 중지 시퀀스를 감지하고, 완료된 항목을 배치에서 제거하는 작업 등을 처리합니다.
이 역시 CPU에서 실행되며,
이를 통해 배칭의 효율성을 극대화하는 데 필요한 메타데이터와 상태를 관리합니다.
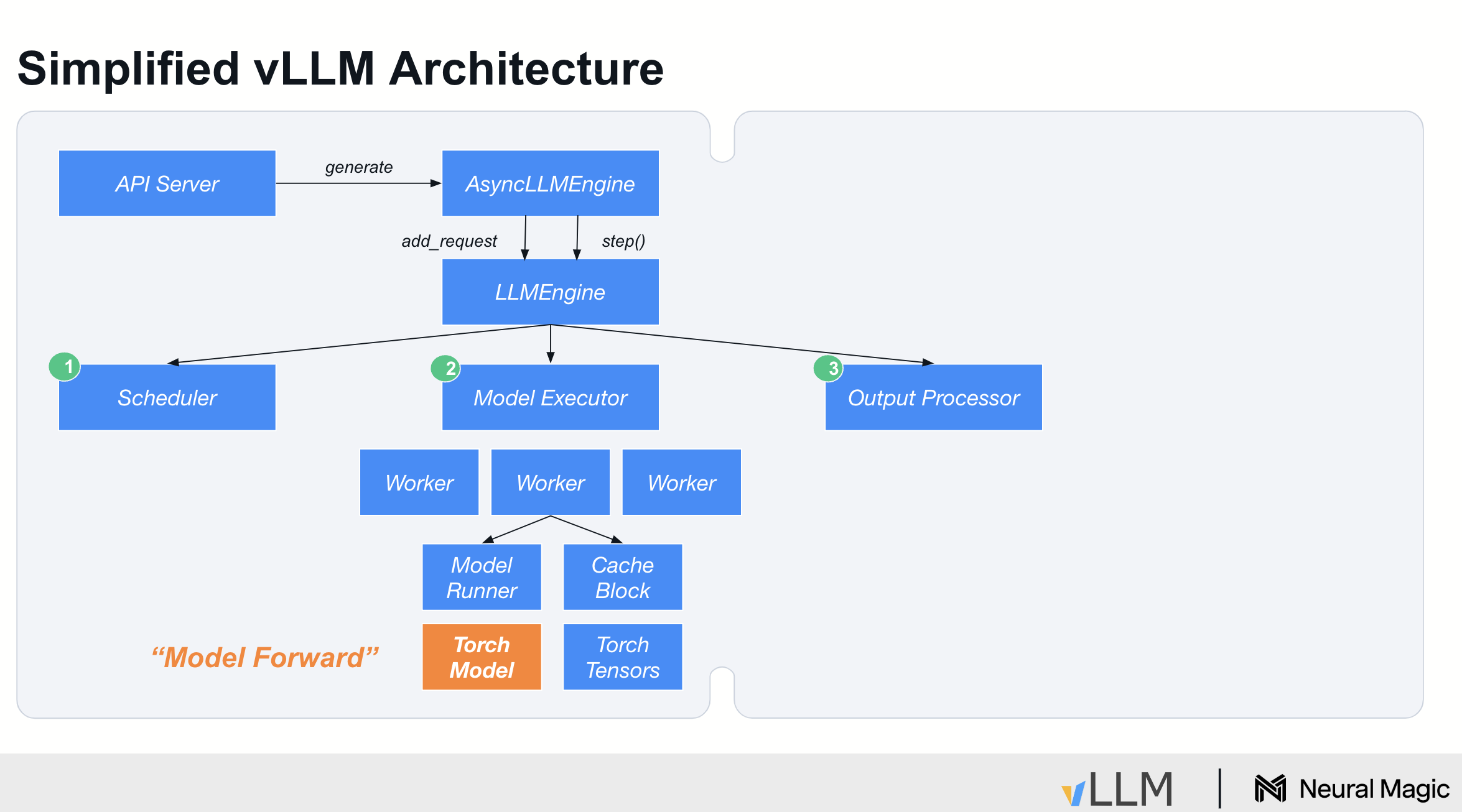
요약하자면, vLLM의 구조는 간단히 보면 이렇게 세 단계로 이루어져 있지만, 실제로는 더 많은 복잡성을 내포하고 있습니다. vLLM 내부에서 모델을 실제로 실행하는 부분은 이 구조의 일부에 불과하며, 상위 수준의 대부분의 코드는 메모리 관리와 작업을 처리하기 위해 필요한 데이터를 전달하는 데 초점이 맞춰져 있습니다. 이를 통해 자동 회귀(autoaggressive) 생성의 높은 처리량을 달성합니다.
ref:
반응형
'vllm' 카테고리의 다른 글
| vLLM 0.5 -> 0.6 버전 디자인 변화만으로 Throughput 2.7배 높이기 (0) | 2025.05.21 |
|---|---|
| vLLM 실행구조 파악하기 (v0.8.4) (1) | 2025.04.20 |
| vllm 도큐먼트로 보는 architecture 개요 (한국어번역+ 코드 추가 ) (1) | 2024.11.24 |