
안녕하세요 vllm 0.5 , 0.6 버전으로의 디자인 변화만으로 throughput 20% 높이기 를 주제를 들고왔습니다. 이전에 포스팅한글인데, v1 아키텍처가 나오면서 부랴부랴 포스팅합니다. 업그레이드가 빠르네요,
vllm 0.6버전 업데이트이후 throughput이 향상되었는데요, 왜 향상 되었을지에 대해서 vllm 디자인과 함께 설명해보고자합니다.
3줄 요약하자면, 다음과 같습니다.
- vLLM 0.6 버전 업데이트 있다.
- GPU 최적화 어느정도 진행해서 CPU 오버헤드가 커보여 개선했다.
- 효과 있다.
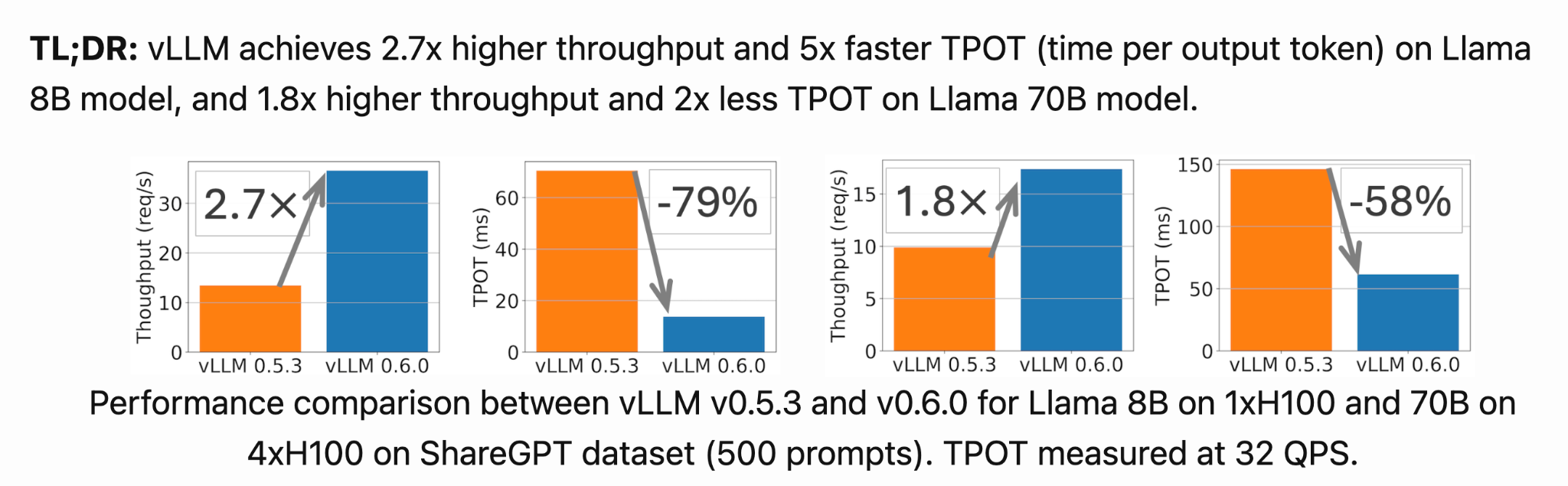
https://blog.vllm.ai/2024/09/05/perf-update.html
- Dataset: ShareGPT 500 prompts randomly sampled from ShareGPT dataset with fixed random seed. ( Average input tokens: 202, average output tokens: 179 )
- Models: Llama 3 8B and 70B.
- Hardware: A100, H100
- Mertics:
이 자료는 vLLM 0.6 버전으로 업데이트된 이후 성능이 향상되었다고 vLLM 공식문서에서 제시한 수치를 바탕으로 작성되었습니다.
위의 링크로 접근하시면 더 자세히 보실 수 있습니다. 이번 버전 업데이트 이후 퍼포먼스 개선을 요약을 보여주는 지표인데요,
먼저, Time-Per-Output-Token, 즉 TPOT은 출력 토큰 하나를 생성하는 데 걸리는 시간(ms)을 의미합니다. TPOT는 32 QPS 환경에서 측정되었습니다.
다음으로 Throughput, 즉 초당 처리 가능한 요청 수를 측정하였는데, 이는 QPS 무한 (QPS inf) 환경, 즉 모든 요청이 한 번에 들어오는 상황에서 측정되었습니다.
보시면, vLLM 버전 업그레이드 이후, 라마3 8B 기준 throughput 2.7배 상승, TPOT -79% 단축 , 라마3 70B 기준 throughput 1.8배 상승, TPOT -58% 단축이라는 지표를 보실 수 있습니다.
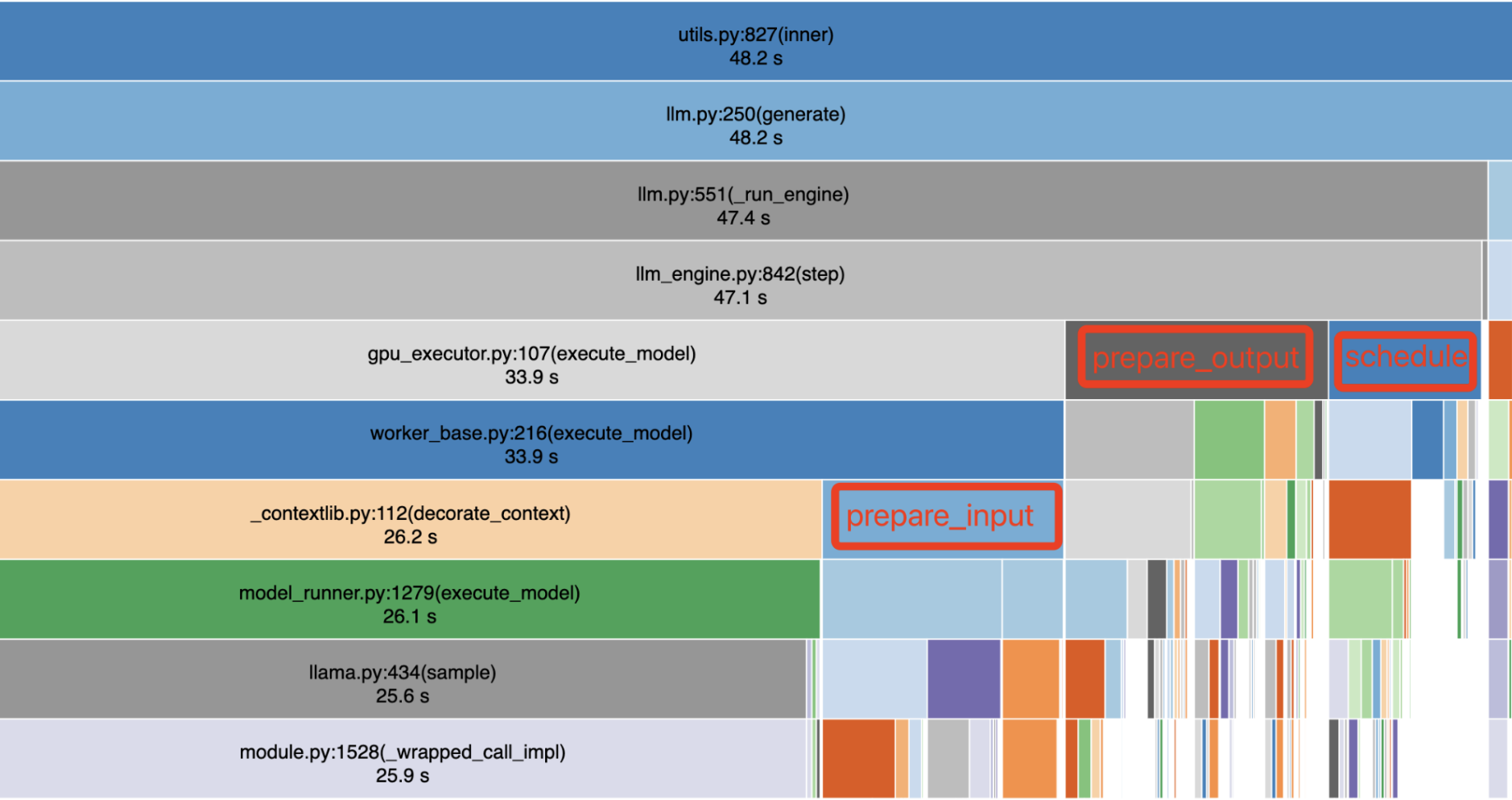
업데이트 사항 공유 이전에 0.5버전대의 vLLM의 성능 병목 현상을 진단결과를 보여드리고 시작하고자 하는데요,
vLLM 의 온라인 inference server 의 경우, fast API 라는 파이썬 웹 프레임워크 중에 가장 빠르다고 알려진 라이브러리로 현재 구동되고 있습니다.
그래서 vLLM 의 성능 진단을 위해 1 H100 GPU에서 실행되는 Llama 3 8B의 fast API profiling 을 일부 발췌했는데요, 따라가보겠습니다.
보시면 위의 48.2 초가 총 걸린 시간이라고 할때, llm_engine.py 에서는 47.1 초가 소요됐네요,
그리고 실제 라마 .py 에서는 25.6초만 소요됩니다.
현재 화면에서 보이는 것 이상의 30% 의 오버헤드가 추가된다는 것을 인지하고 있을때, 리퀘스트를 던져서 받기까지의 과정에서 GPU 소요시간은 38% 밖에 안되는 것을 인지할 수 있습니다.

다음 장표들에서 좀더 자세히 설명드리겠지만, vLLM 에서 LLM inference에서는 CPU와 GPU 간의 commnunication 과정ㅇ이 필수적입니다. 주요 계산은 GPU에서 이루어지지만, CPU는 요청을 서빙하고 스케줄링하는 데 중요한 역할을 합니다. 만약 CPU가 충분히 빠르게 스케줄링하지 못하면, GPU가 CPU를 기다리며 유휴 상태에 놓이게 되어 GPU 활용 효율이 떨어지고 inference 성능에 부정적인 영향을 미치게 됩니다.
1년 전 vLLM이 처음 출시되었을 때는 주로 메모리가 제한된 GPU(예: NVIDIA A100-40G에서 Llama 13B 실행)에 상대적으로 큰 모델을 최적화하는 데 초점을 맞췄습니다. 하지만 NVIDIA H100과 같은 더 빠르고 메모리가 큰 GPU가 보편화되고, GQA나 양자화(quantization)와 같은 추론 최적화 기술이 도입되면서, CPU에서 소요되는 시간이 주요 병목이 되고 있습니다.
특히, Llama 3 8B 모델을 1개의 NVIDIA H100 GPU에서 실행한 프로파일링 결과는 좀더
GPU에서 LLM 실행 자체에는 전체 시간의 38%만 사용. HTTP API server에서 총 실행 시간의 33%를 사용.스케줄링 작업에서 총 실행 시간의 29% 소요됩니다. (여기에는 LLM의 마지막 단계 결과를 수집하고, 다음 단계 실행 요청을 스케줄링하며, 이 요청들을 LLM 입력으로 준비하는 작업이 포함됨.)
이 분석을 통해 vLLM에서 두 가지 주요 문제를 확인할 수 있었습니다.
주요 문제점
- 높은 CPU 오버헤드
vLLM의 CPU 구성 요소가 예상보다 많은 시간을 소비하고 있습니다. 이는 vLLM 코드가 이해하기 쉽고 기여하기 용이하도록 Python 중심으로 작성되었기 때문입니다. Python의 네이티브 데이터 구조(예: Lists와 Dicts)를 많이 사용하는 것이 스케줄링 및 데이터 준비 시간 증가로 이어졌습니다. - 비동기화 부족
vLLM의 여러 구성 요소(예: 스케줄러 및 출력 처리기)가 GPU 실행을 차단하는 동기 방식으로 실행되고 있습니다. 동기 방식은 GPU가 CPU 작업을 기다리게 만들어 GPU 활용도를 낮추는 문제를 발생시켰습니다.
vLLM의 성능 병목은 주로 GPU 실행을 차단하는 CPU 오버헤드에서 비롯됩니다.
이를 해결하기 위해 vLLM v0.6.0에서는 이러한 오버헤드를 최소화하기 위한 일련의 최적화 방안을 도입한게 이번 변경점의 포인트라고 보시면 될것같습니다.
vLLM architecture
이해를 돕기 위해 간략화된 vllm 디자인 대해 설명드리겠습니다.

사실 llm 에서 우리가 원하는 사항은 많습니다.
예를들어
오프라인 inference 에서 이용하고 싶다던지,
아니면 온라인 inference 에서도 completions(주어진 prompt에 대해, 모델은 하나 이상의 예측된 completion을 반환합니다. 이와 함께 각 위치에서 대체 tokens의 확률도 제공), , Embeddings ( 주어진 입력값에 대한 벡터 표현을 생성하기 )같이 다양한 요구사항들이 있기때문에
LLM Class, Api server, Async LLMEngine 등이 생겼고, 결국에 온라인, 오프라인 요구 사항 관계없이 다들 LLMEngine 을 호출하는 과정이라 생각해주시면 될 것같습니다.
뭐로 가던 LLMEngine로 가는 것이 목표라고 봐주시면 될것같습니다.
LLMEngine과 AsyncLLMEngine 클래스는 vLLM 시스템의 핵심으로, model inference과 비동기 요청 처리를 담당합니다.
LLMEngine 클래스는 vLLM engine의 핵심 구성 요소입니다. 이 클래스는 클라이언트로부터 요청을 받아 모델에서 출력값을 생성하는 역할을 합니다.
LLMEngine은 input processing, , scheduling, model execution(다중 호스트와/또는 GPU에 걸쳐 분산 실행될 가능성이 있음) 그리고 output processing을 포함합니다.
- Input Processing: 지정된 tokenizer를 사용하여 입력 텍스트를 tokenization합니다.
- Scheduling: 각 단계에서 어떤 요청을 처리할지 결정합니다.
- Model Execution: 언어 모델의 실행을 관리하며, 여러 GPU에 걸쳐 분산 실행을 포함합니다.
- Output Processing: 모델에서 생성된 출력값을 처리하며, 언어 모델의 token ID를 사람이 읽을 수 있는 텍스트로 디코딩합니다.
사실 이 그림이 이번 글에서 제일 핵심 맵입니다. 계속 반복할거니까 눈여겨봐주세요.

아까 llm 구조에서 그러면 어떻게 Model 이 excution 되느냐 하면,
먼저 Worker에 대해 이야기해보겠습니다.
Worker는 모델 inference를 실행하는 프로세스를 의미합니다.
vLLM에서는 GPU와 같은 하나의 accelerator device를 하나의 프로세스로 제어하는 방식을 따릅니다.
예를 들어, tensor parallelism 크기가 2이고 pipeline parallelism 크기가 2라면, 총 4개의 Workers가 생성됩니다.
Workers는 두 가지로 식별됩니다:
- rank: 전역적인 오케스트레이션 용도로 사용
- local_rank: accelerator device를 할당하거나, 파일 시스템 및 shared memory와 같은 로컬 리소스에 접근할 때 사용
다음은 Model Runner입니다.
각 Worker는 하나의 Model Runner 객체를 가지고 있습니다.
이 Model Runner는 모델을 로드하고 실행하는 역할을 담당합니다.
모델 실행의 주요 로직이 여기 포함되어 있는데요.
예를 들어:
- input tensors를 준비하거나
- CUDA graphs를 캡처하는 작업이 이 단계에서 진행됩니다.
마지막으로 Model입니다.
각 Model Runner 객체는 하나의 Model Object를 가지고 있는데, 이는 실제 torch.nn.Module의 인스턴스입니다.
여기까지가 vllm 디자인 설명이었습니다.
vLLM 0.6의 주요 아키텍처 변경사항 변경사항

여기서 그럼 vLLM 0.6의 주요 아키텍처 변경사항 변경사항의 경우는 다음과 같습니다.
- 비동기에서 Multi-Process + IPC로 전환
- Multi-Step Scheduling
- 비동기 Output Processing
1. 비동기에서 Multi-Process + IPC로 전환

OpenAI protocol에 맞춰 network request를 관리하고 response를 포맷팅하는 작업이 특히 token streaming이 활성화된 고부하 환경에서 많은 CPU cycle을 소모한다는 것을 확인했습니다.
예를 들어, Llama3 8B 모델은 가벼운 부하에서 13ms마다 1 token을 생성합니다. 이 경우, frontend는 초당 76개의 object를 streaming해야 하며, 동시 요청이 수백 개로 늘어나면 이 요구는 더욱 증가합니다.
이전 vLLM 구조에서는 API server와 inference engine이 같은 프로세스에서 실행되었기 때문에, Python GIL을 놓고 경쟁하는 상황이 발생했고, 이는 CPU contention을 유발했습니다.
그래서 이전에는 LLM Engine이 비동기 루프에 의존했던 방식을 vLLM 0.6에서는 Multi-Process 아키텍처와 ZeroMQ를 사용한 IPC로 전환하여 이벤트 루프에서 발생하던 CPU 오버헤드를 크게 줄였습니다.그리고, 큐에서 데이터를 가져오고 생성자에 푸시하는 방식 대신, 메시지 전달 프로토콜로 zeromq를 사용했습니다. 이 구조는 CPU 리소스를 많이 소모하는 두 컴포넌트가 서로 독립적으로 작동할 수 있도록 설계되었습니다.
Splitting the API server into a separate process enables overlapping server work with engine work, sidestepping Python’s GIL

이렇게 API server와 engine을 분리하는 구조를 통해,
API server는 request validation, tokenization, JSON formatting 작업을 처리하며,
engine은 request scheduling과 model inference를 담당합니다. 두 프로세스는 ZMQ로 연결되어 낮은 overhead를 유지하며 상호작용합니다.
이 변경을 통해 GIL 경쟁을 없애고, 두 컴포넌트가 더 효율적으로 작동할 수 있도록 했습니다. 결과적으로 CPU contention 문제가 해결되었고, 전반적인 성능이 향상되었습니다.
라마 3 8B 기준 throughput 25% 향상이라고 합니다.
2. 스케줄링 방식 변경
두번째로 스케줄링 방식의 변경입니다.
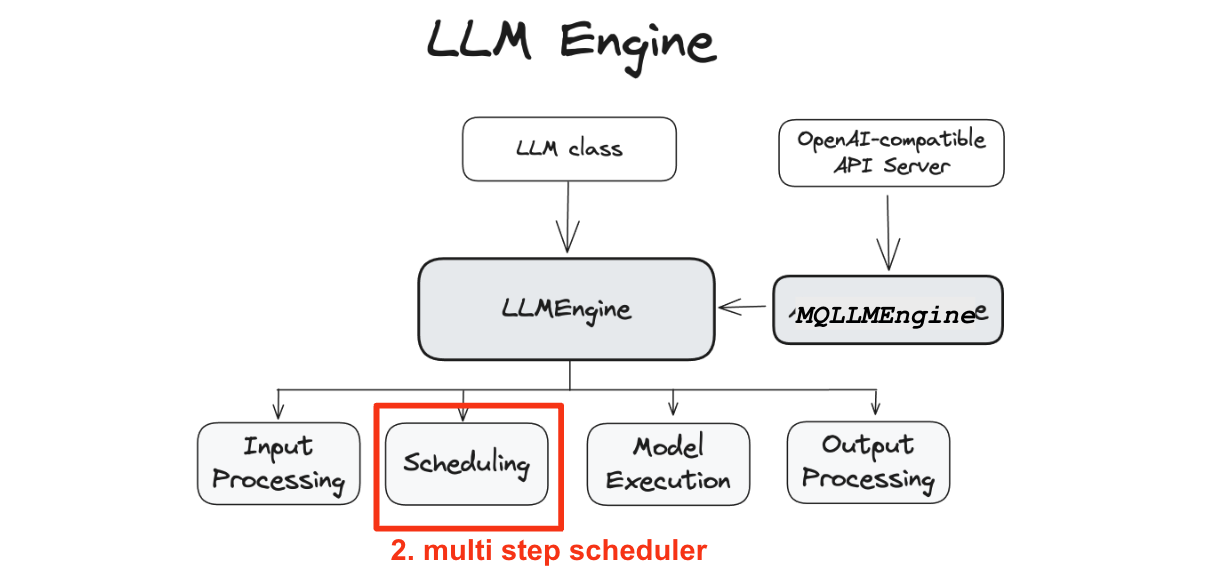

각 디코딩 배치마다 발생하는 CPU 오버헤드는 입력/출력 처리와 생성 과정에서 비롯됩니다 Multi-step 스케줄링은 이러한 오버헤드를 n-스텝에 걸쳐 분산하여 효율성을 높이는 접근 방식입니다.
오버헤드 요약:
- GPU -> CPU로의 sampled token 전송: de-tokenization 및 클라이언트 응답을 위해 필요한 단계입니다.
- 출력 생성: tensor를 Python 객체로 변환(Pythonization)하는 과정이 포함됩니다.
- 다음 스텝 입력 메타데이터 생성 및 준비: 디코딩 진행을 위해 필수적으로 수행해야 합니다.
- vLLM Scheduler 실행: 디코딩 작업을 관리하기 위한 프로세스입니다.
결과적으로 GPU가 CPU 작업을 기다리며 자주 idle 상태로 전환되며, 이로 인해 5-13ms의 GPU bubble이 발생하는 것을 확인합니다.
Multi-step decoding은 여러 번의 디코딩 패스를 수행한 후 GPU-CPU sync를 실행하여 vLLM scheduler를 호출하고 sampled token을 처리하는 방식입니다. 현재는 각 디코딩 단계마다 GPU->CPU 메모리 전송이 동기적으로 수행되며, 이로 인해 GPU bubble이 발생합니다. 반면 Multi-step 방식을 적용하면 메모리 전송이 별도의 CUDA stream에서 비동기적으로 이루어지며 CPU가 GPU보다 먼저 실행될 수 있어 GPU bubble을 효과적으로 줄이는 결과를 가져옵니다.
Multi-step 방식을 도입함으로써 GPU와 CPU 간의 자원 활용 불균형을 해소하고, 디코딩 프로세스의 효율성을 대폭 향상시킬 수 있음을 제안합니다.
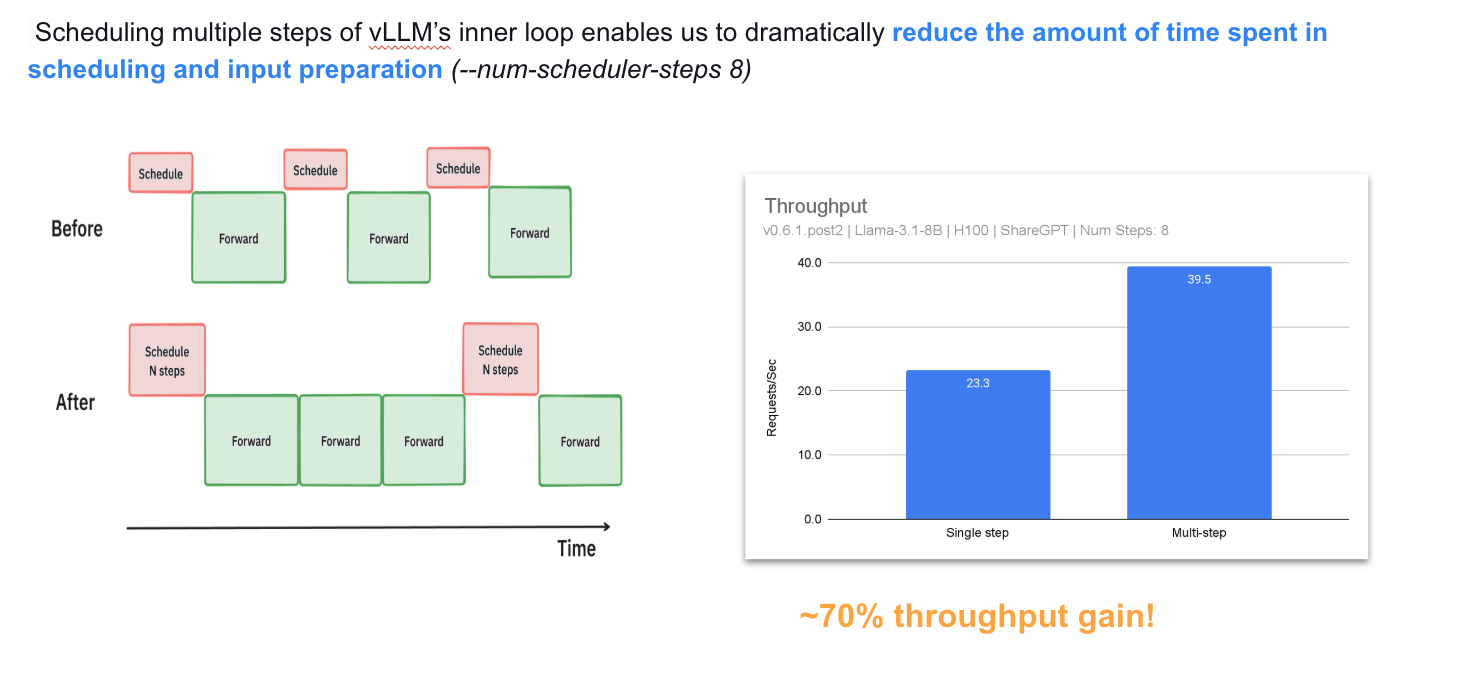
개선 그림을 보자면,
scheduling과 input preparation을 한 번에 처리한 뒤, 모델이 n번의 연속적인 step 동안 실행되도록 하는 비포 애프터를 확인할 수 있습니다.
이를 통해 GPU가 각 step 사이에 CPU를 기다리지 않고 지속적으로 처리할 수 있도록 하여, CPU overhead를 여러 step에 분산시키고 GPU idle time을 대폭 줄였습니다.
그 결과, Llama 8B 모델을 1xH100 환경에서 실행할 때 throughput이 약 70% 향상되는 성과를 얻었습니다.
3. Async Output Processing
마지막으로 Async Output Processing 업데이트 입니다. 출력 처리를 비동기 방식으로 재구성하여, 블로킹 작업을 최소화하고 토큰 생성 및 전달 속도를 높였습니다.

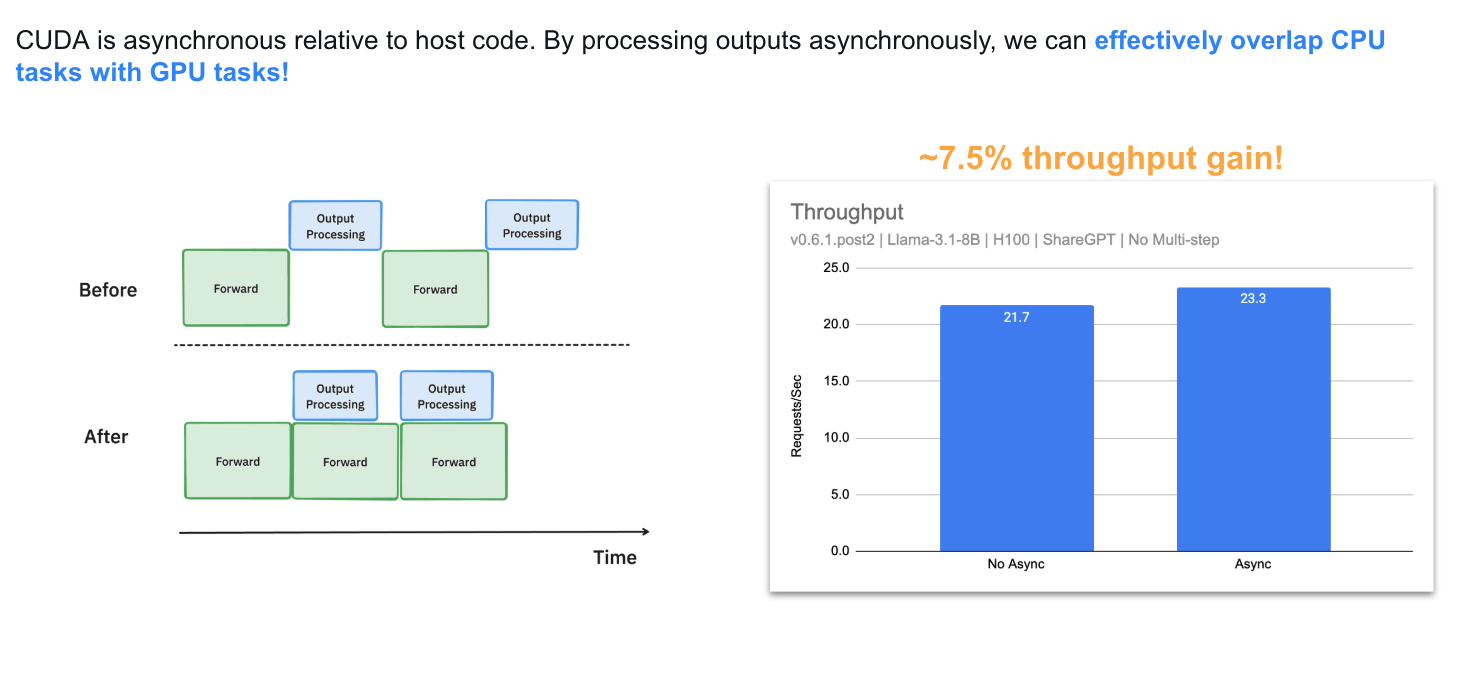
요약하자면, 출력 데이터 구조 처리를 위한 CPU 작업을 GPU 계산과 겹치게 하여 GPU 유휴 시간을 줄이고 처리량을 개선했습니다.
GPU 활용률을 최대화하기 위한 노력의 일환으로, vLLM에서 model output 처리를 대대적으로 개선했습니다.
기존에는, 매 토큰을 생성한 후 vLLM은 GPU에서 CPU로 model output을 이동시킨 뒤, stopping 토큰을 확인하여 요청이 완료되었는지 판단하고 다음 단계를 실행했습니다.
이 과정은 생성된 token IDs를 디토크나이즈하고 문자열 매칭을 수행하는 작업이 포함되어 있어, batch size가 커질수록 오버헤드가 증가하는 문제가 있었습니다.
이 비효율성을 해결하기 위해, 우리는 비동기 output processing을 도입하여 output processing과 model execution을 병렬 처리하도록 했습니다. 이제 vLLM은 output을 즉시 처리하지 않고, n번째 단계의 output 처리를 지연시켜 n+1번째 단계 실행 중에 수행합니다.
이 방식은 1xH100에서 Llama3 8B 모델 실행 시, throughput을 7.5% 개선했습니다.
최종 요약
최종 변경 지점을 요약한 그림을 그려보았습니다.

결과 실험 공유
- 서빙 엔진: vLLM v0.6.0을 TensorRT-LLM r24.07, SGLang v0.3.0, 그리고 lmdeploy v0.6.0a0와 비교하여 벤치마킹.
vLLM에서는 --num-scheduler-steps 10 옵션을 설정하여 멀티스텝 스케줄링(multistep scheduling)을 활성. - 데이터셋 (Dataset) : ShareGPT, Prefill-heavy dataset, Decode-heavy dataset
- 모델 (Models) : Llama 3 8B, Llama 3 70B
- 하드웨어 (Hardware) : A100과 H100 GPU를 사용
- 메트릭스 (Metrics): Time-to-first-token (TTFT, 단위: ms), Time-per-output-token (TPOT, 단위: ms), Throughput (단위: requests per second)


Limitations and Future Works

한계로는
1. 잔존하는 CPU 오버헤드가 있습니다. 개선에도 불구하고, 입력 처리 및 스케줄러 실행과 같은 CPU 작업이 여전히 총 시간의 22%를 차지합니다.
2. 또한, 대형 모델 확장성이있는데요, Llama 8B와 70B 모델에서, 그리고 스케줄링이 개선 효과를 보였으나, 더 큰 모델에서는 개선 효과가 감소할 가능성이 있습니다.
따라서, 해당 부분의 개선이 필요하니다.
- 비동기 입력 처리: 입력 처리에서 비동기 메커니즘을 도입하여 CPU 소요 시간을 추가적으로 줄이는 방안이 연구돼야하고,
- 향상된 스케줄러 최적화: 워크로드 동적 특성에 적응할 수 있는 우선순위 기반 또는 적응형 스케줄러 연구가 필요합니다.
GPU 의 성능이 좋아지고 빨라질 수록
CPU 에서 병목지점이 생길것이다.
디자인 개선을 통해 CPU 최적화에 대한 고민을 이어가야만, throughput, TPOT, TFFT 를 향상시킬 수 있다라고 결론 지을 수 있을것 같습니다.
Conclusion
결론적으로 vLLM 0.5에서 vLLM 0.6로의 전환은 GPU 관련 변경 없이도 성능을 크게 향상을 보여줬고, 변경지점은 Multi-Process 아키텍처, Multi-Step Scheduling, 비동기 Output Processing 였다. 라고 결론 지으며 해당 포스팅을 마무리하겠습니다.
감사합니다.

- Dataset: ShareGPT 500 prompts randomly sampled from ShareGPT dataset with fixed random seed. ( Average input tokens: 202, average output tokens: 179 )
- Models: Llama 3 8B and 70B.
- Hardware: A100, H100
- Mertics:
'vllm' 카테고리의 다른 글
| vLLM 실행구조 파악하기 (v0.8.4) (1) | 2025.04.20 |
|---|---|
| vllm 도큐먼트로 보는 architecture 개요 (한국어번역+ 코드 추가 ) (1) | 2024.11.24 |
| 2024.09.19 Neural Magic Office Hour 에서 확인하는 vLLM 아키텍처 (0) | 2024.11.24 |